Garis besar topik
-
ARIMA sering juga disebut metode runtun waktu Box-Jenkins. ARIMA sangat baik ketepatannya untuk peramalan jangka pendek, sedangkan untuk peramalan jangka panjang ketepatan peramalannya kurang baik. Biasanya akan cenderung flat (mendatar/konstan) untuk periode yang cukup panjang. Model Autoregresif Integrated Moving Average (ARIMA) adalah model yang secara penuh mengabaikan independen variabel dalam membuat peramalan. ARIMA menggunakan nilai masa lalu dan sekarang dari variabel dependen untuk menghasilkan peramalan jangka pendek yang akurat. ARIMA cocok jika observasi dari deret waktu (time series) secara statistik berhubungan satu sama lain (dependent). Tujuan model ini adalah untuk menentukan hubungan statistik yang baik antar variabel yang diramal dengan nilai historis variabel tersebut sehingga peramalan dapat dilakukan dengan model tersebut.
Model ARCH & GARCH
ARCH/GARCH adalah suatu model peramalan/forecasting time series yang digunakan dalam single equation artinya hanya menggunakan satu variabel saja. Dengan menggunakan informasi periode data yang lalu dapat meramal nilai data untuk periode yang akan datang. ARCH/GARCH biasanya digunakan untuk mencari volitalitas suatu data. Yang dilihat adalah pengaruh varian dan error kuadrat dari series datanya. ARCH/GARCH adalah kelanjutan dari peramalam model ARIMA, dimana syarat yang digunakan apabila model ARIMA yang dipilih tidak memenuhi asumsi homokedastisitas artinya modelnya masih mengandung heterokedastistas.Sehingga akan didapat beberapa model ARCH/GARCH. Setelah model didapat biasanya yang dipilih adalah model yang signifikan, error terkecil, bias proportion terkecil, korelasinya tinggi serta memenuhi asumsi normalitas dan homokedastisitas barulah model tersebut dapat digunakan untuk melakukan forecast/peramalan untuk nilai data periode berikutnya.Perilaku ΓÇ£volatileΓÇ¥ dalam pasar finansial biasanya dirujuk sebagai ΓÇ£volatilitasΓÇ¥. Volatilitas telah menjadi konsep yang penting dalam teori dan praktek finansial, seperti managemen risiko, pemilihan portofolio dan sebagainya. Dalam kajian secara statistik, biasanya diukur menggunakan variansi atau standar deviasi. Engle (1982) telah berhasil mengembangkan suatu model volatilitas untuk data runtun waktu finansial yang dikenal dengan model Autoregressive Conditional Heteroscedasticity (ARCH). Sedangkan Bollerslev (1986) telah mengembangkan model volatilitas yang lebih fleksibel yang dikenal sebagai Generalized Autoregressive Conditional Heteroscedasticity (GARCH).
-
Siswa harusTandai selesai
1. Logistic didasarkan pada kondisi dimana variabel tak bebasnya bersifat kualitatif (menggunakan fungsi logit)
Y = a + bX....dimana Y = kualitatif ----> Regresi Logit
2. Probit didasarkan pada kondisi dimana variabel tak bebasnya bersifat kuantitatif(menggunakan distribusi kumulatif normal --> Probabilita ΓÇÿSuksesΓÇÖ)
Y = a + bX...dimana X = kualitatif ---> regresi probit
3. Dalam prakteknya kedua model seringkali memberikan hasil yang sama/mirip.
4. Logit lebih mudah diinterpretasikan. -
Siswa harusTandai selesai
Regresi logistik adalah sebuah pendekatan untuk membuat model prediksi seperti halnya regresi linear atau yang biasa disebut dengan istilah Ordinary Least Squares (OLS) regression. Perbedaannya adalah pada regresi logistik, peneliti memprediksi variabel terikat yang berskala dikotomi. Skala dikotomi yang dimaksud adalah skala data nominal dengan dua kategori, misalnya: Ya dan Tidak, Baik dan Buruk atau Tinggi dan Rendah.
Apabila pada OLS mewajibkan syarat atau asumsi bahwa error varians (residual) terdistribusi secara normal. Sebaliknya, pada regresi ini tidak dibutuhkan asumsi tersebut sebab pada regresi jenis logistik ini mengikuti distribusi logistik.
Asumsi Regresi Logistik antara lain:
- Regresi logistik tidak membutuhkan hubungan linier antara variabel independen dengan variabel dependen.
- Variabel independen tidak memerlukan asumsi multivariate normality.
- Asumsi homokedastisitas tidak diperlukan
- Variabel bebas tidak perlu diubah ke dalam bentuk metrik (interval atau skala ratio).
- Variabel dependen harus bersifat dikotomi (2 kategori, misal: tinggi dan rendah atau baik dan buruk)
- Variabel independen tidak harus memiliki keragaman yang sama antar kelompok variabel
- Kategori dalam variabel independen harus terpisah satu sama lain atau bersifat eksklusif
- Sampel yang diperlukan dalam jumlah relatif besar, minimum dibutuhkan hingga 50 sampel data untuk sebuah variabel prediktor (independen).
- Dapat menyeleksi hubungan karena menggunakan pendekatan non linier log transformasi untuk memprediksi odds ratio. Odd dalam regresi logistik sering dinyatakan sebagai probabilitas.
Model Persamaan Regresi Logistik
Model persamaan aljabar layaknya OLS yang biasa kita gunakan adalah berikut: Y = B0 + B1X + e. Dimana e adalah error varians atau residual. Dengan model regresi ini, tidak menggunakan interpretasi yang sama seperti halnya persamaan regresi OLS. Model Persamaan yang terbentuk berbeda dengan persamaan OLS.
Berikut persamaannya:

Persamaan Regresi Logistik Ln: Logaritma Natural.Di mana:
B0 + B1X: Persamaan yang biasa dikenal dalam OLS.
Sedangkan P Aksen adalah probabilitas logistik yang didapat rumus sebagai berikut:
Probabilitas Regresi Logistik Di mana:
exp atau ditulis ΓÇ£eΓÇ¥ adalah fungsi exponen.
(Perlu diingat bahwa exponen merupakan kebalikan dari logaritma natural. Sedangkan logaritma natural adalah bentuk logaritma namun dengan nilai konstanta 2,71828182845904 atau biasa dibulatkan menjadi 2,72).
Dengan model persamaan di atas, tentunya akan sangat sulit untuk menginterprestasikan koefisien regresinya. Oleh karena itu maka diperkenalkanlah istilah Odds Ratio atau yang biasa disingkat Exp(B) atau OR. Exp(B) merupakan exponen dari koefisien regresi. Jadi misalkan nilai slope dari regresi adalah sebesar 0,80, maka Exp(B) dapat diperkirakan sebagai berikut:

Nilai Odds Ratio
Besarnya nilai Exp(B) dapat diartikan sebagai berikut:
Misalnya nilai Exp (B) pengaruh rokok terhadap terhadap kanker paru adalah sebesar 2,23, maka disimpulkan bahwa orang yang merokok lebih beresiko untuk mengalami kanker paru dibadningkan dengan orang yang tidak merokok. Interprestasi ini diartikan apabila pengkodean kategori pada tiap variabel sebagai berikut:
- Variabel bebas adalah Rokok: Kode 0 untuk tidak merokok, kode 1 untuk merokok.
- Variabel terikat adalah kanker Paru: Kode 0 untuk tidak mengalami kanker paru, kode 1 untuk mengalami kanker paru.
Pseudo R Square
Perbedaan lainnya yaitu pada regresi ini tidak ada nilai ΓÇ£R SquareΓÇ¥ untuk mengukur besarnya pengaruh simultan beberapa variabel bebas terhadap variabel terikat. Dalam regresi logistik dikenal istilah Pseudo R Square, yaitu nilai R Square Semu yang maksudnya sama atau identik dengan R Square pada OLS.
Jika pada OLS menggunakan uji F Anova untuk mengukur tingkat signifikansi dan seberapa baik model persamaan yang terbentuk, maka pada regresi ini menggunakan Nilai Chi-Square. Perhitungan nilai Chi-Square ini berdasarkan perhitungan Maximum Likelihood.
Untuk melihat contoh penelitian yang menggunakan regresi logisti silahkan anda lihat pada file Pdf dan utk praktikum dan tutorial penggunaan regresi data logit bisa anda lihat pada tayangan sbb:
-
Siswa harusTandai selesai
Tujuan Menggunakan regresi Logistik
Pemahaman tujuan menggunakan regresi logistik sangat diperlukan sebelum anda menggunakannya sebagai alat penelitian. Anda bisa mendalami dan membahas secara detil jika tujuan penggunaan regresi logistik anda kuasai secara detil. Setelah saya membaca beberapa jurnal yang menggunakan regresi logistik, saya menyimpulkan tujuan penggunaan regresi logistik secara umum ada tiga, yakni:
1. Menghitung peluang
Persamaan yang diperoleh dari proses regresi logistik, dapat digunakan untuk menghitung peluang responden diluar responden yang termasuk dalam penelitian. Contoh yang dapat dipahami adalah proses pengajuan kredit. Pihak bank biasanya melakukan evaluasi kelayakan seseorang layak atau tidak untuk menerima kredit pinjaman dari bank. Beberapa pertanyaan diberikan kepada pihak bank terhadap calon penerima kredit. Pertanyaan yang diberikan seputar karakteristik variabel calon penerima modal tersebut merupakan variabel independen yang akan diinput oleh petugas bank kedalam model. Dari beberapa variabel yang dipertanyakan itulah, petugas bank dapat menentukan peluang calon penerima kredit tersebut untuk bisa mengembalikan pinjaman atau tidak, nilai antara 0 ΓÇô 1.
Tentunya model yang digunakan oleh petugas bank adalah model regresi logistik berdasarkan data-data peminjam sebelumnya. Dalam model tersebut terdapat komponen bahwa biasanya peminjam yang memiliki pendapatan dibawah sekian dengan pinjaman yang telah dimiliki sebelumnya sekian, ditambah tanggungan kerja sekian, memiliki peluang untuk mengembalikan pinjaman sebesar sekian ( nilai 0 -1).
2. Melihat karakteristik
Tujuan kedua ini sering digunakan untuk melihat perbedaan karakteristik antara 2 kelompok. Salah satunya adalah skripsi saya yang saya sebutkan diatas. Skripsi tersebut menggambarkan karakteristik petani anorganik dan petani organik. Hasil kesimpulan bahwa peluang petani mampu beralih dari anorganik ke organik adalah karena perbedaan harga produk hasil kedua proses tersebut. Petani organik bersedia beralih dari anorganik ke organik meskipun produktivitas organik lebih kecil dibanding anorganik. Namun, perbedaan harga yang tinggi menjadikan petani organik memiliki pendapatan yang lebih tinggi dibandingkan petani anorganik.
Tujuan melihat karakteristik ini biasanya membahas nilai odds ratio di masing masing variabel independen (nilai odds ratio adalah (exp(koefisien)) masing-masing variabel). Nilai odds ratio menjelaskan peluang responden beralih ke organik (contoh kasus diatas). Penjelasan nilai odds ratio berbeda dari nilai koefisien regresi pada umumnya. Bila koefisien regresi menjelaskan : ΓÇ£ jika variabel X naik 1 satuan, maka nilai Y akan naik sebesar nilai koefisien satuanΓÇ¥ maka exp(koefisien) atau odds ratio pada regresi logistik menjelaskan : ΓÇ£ responden yang memiliki variabel x lebih tinggi, maka akan berpeluang untuk memilih organik (contoh kasus diatas) sebesar ΓÇ£exp(nilai koefisien) atau biasa disebut odds ratioΓÇ¥ kali dibandingkan responden yang memiliki variabel x lebih rendahΓÇ¥. Iya, nilai exp(koefisien) pada regresi logistik atau disebut sebagai odds ratio menjelaskan peluang, dan tidak menjelaskan berapa yang dimaksud ΓÇ£lebih tinggiΓÇ¥ dari variabel X tersebut.
3. Faktor Yang mempengaruhi
Tujuan ketiga ini merupakan pengembangan dari tujuan kedua, peneliti mampu mengetahui faktor yang mempengaruhi mengapa terdapat perbedaan antara kedua kelompok tersebut. Nilai odds ratio yang tinggi menandakan varaibel tersebut memiliki pengaruh yang tinggi terhadap pemilihan beda dari responden. Tujuan untuk mengetahui faktor yang mempengaruhi ini adalah diharapkan faktor yang signifikan mempengaruhi tersebut merupakan faktor yang bisa diatur oleh peneliti atau pengambil kebijakan sehingga bisa menggiring responden lainnya untuk berbuat yang sama terhadap responden yang bernilai 1 sebelumnya.
Contoh pada skripsi ini adalah bahwa harga merupakan faktor yang paling berpengaruh terhadap preferensi petani memilih pertanian organik, maka pemerintah jika ingin mengembangkan pertanian organik harus melakukan kebijakan yang tetap menstabilkan harga agar terus berada diatas harga produk anorganik sehingga peminat petani organik akan sebakin banyak dan bisa terus berkembang.
Untuk megolah data dengan menggunakan persamaan Regresgi logit, silhahkan anda cek PPT sebagai berikut:
-
Siswa harusTandai selesai
Pada kesempatan kali ini kita akan membahas salah satu model regresi Y dummy (varibel boneka) lainnya yang akan memperbaiki model peluang linear dan secara kebagusan model sama dengan model logit yaitu model probit. Dimana secara nyata akan memperbaiki dua aspek sekaligus yaitu letak nilai peluang yang dihasilkan oleh model pasti berada pada selang 0 Γëñ P Γëñ 1 dan dipenuhinya asumsi homoskedastisitas pada model dikarenakan pada model probit dikenai proses pembobotan. Jadi, model probit ini menyempurnakan model sebelumnya yaitu model peluang linear dan secara perlakuan data sama dengan model logit.
Model PROBIT
Apabila model logit menggunakan fungsi peluang logistik kumulatif (logit), maka model probit menggunakan fungsi peluang normal kumulatif, oleh karena itu kadang-kadang model probit disebut dengan model normit (normit model). Pada prinsipnya model probit serupa dengan model logit, kecuali model logit menggunakan fungsi peluang logistik kumulatif sedangkan model probit menggunakan fungsi peluang normal kumulatif. Model probit dapat dinyatakan, sebagai berikut :

Dimana F menunjukkan fungsi peluang kumulatif sedangkan Xi menunjukkan variabel bebas yang bersifat stokastik.
Oleh karena model peluang probit berkaitan dengan fungsi peluang normal kumulatif, maka kita dapat menulis model peluang probit sederhana, sebagai berikut :

Oleh karena dalam persamaan di atas Pi menunjukkan peluang bahwa suatu kejadian akan terjadi, maka dapat diukur melalui daerah di bawah kurva normal baku dari – ∞ sampai dengan Zi.
Untuk memperoleh suatu dugaan dari indeks Zi, maka kita dapat menggunakan invers dari fungi normal kumulatif (Lihat tabel normal baku Z sebagai bantuan), sehingga diperoleh :

Kita dapat menginterpretasikan peluang Pi yang dihasilkan dari model probit sebagai suatu dugaan dari peluang bersyarat (conditional probability) bahwa suatu objek pengamatan atau kelompok akan mengalami suatu kejadian berdasarkan nilai tertentu dari variabel X.
Hal ini akan serupa dengan peluang bahwa variabel normal baku Zi akan lebih kecil atau sama dengan ╬▓0 + ╬▓1 X1i atau P(Zi Γëñ ╬▓0 + ╬▓1 X1i), dimana besar nilai peluang tersebut dapat dilihat dari tabel distribusi normal kumulatif.
Persamaan Zi di atas merupakan persamaan yang linear dalam parameter, sehingga dapat diduga dengan menggunakan metode kuadrat terkecil (OLS).
Karena Pi_Topi (rumus pada artikel : Model Logit) merupakan peluang dibawah kurva normal dari nilai Zi, maka terdapat masalah dalam menggunakan metode kuadrat terkecil untuk pendugaan kasus data berkelompok. Jika kita mengasumsikan setiap objek pengamatan dalam kelompok adalah bebas dan mengikuti distribusi peluang binomial, maka variabel takbebas dari persamaan di atas akan mendekati distribusi normal (apabila ukuran sampel besar) yang memiliki nilai rata-rata nol (0) dan varians sebesar:

Hal lain bahwa persamaan di atas akan memiliki sifat heteroskedastik. Untuk mengatasi hal tersebut, maka persamaan tersebut diduga dengan menggunakan metode kuadrat terkecil terbobot (weighted least square method), dengan jalan melakukan pembobotan terhadap setiap nilai pengamatan melalui penggandaan dengan pembobot Wi = 1/√Vi.
Untuk memudahkan pemahaman terhadap penurunan perumusan secara matematis tersebut di atas, berikut disajikan tabel perhitungan secara manual atas data dengan konsep logit (kasus data berkelompok ΓÇô rancangan percobaan) sebagai berikut,
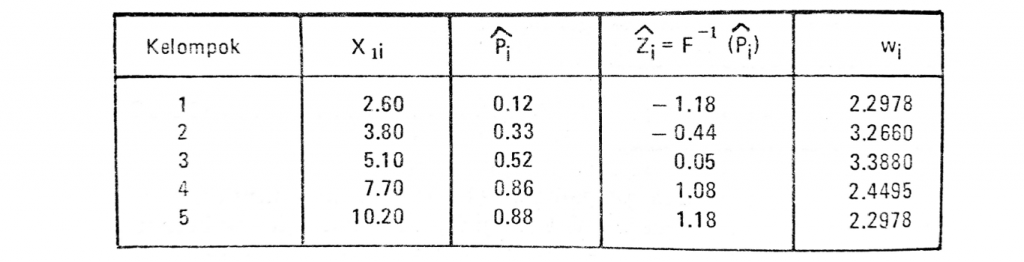
Gambar 1. Penaksiran Model Probit Data Berkelompok
Dari fungsi data di atas regresi dapat dilakukan antara variabel Zi dengan variabel X dengan sebelumnya dilakukan pemobobotan pada masing-masing variabel. Untuk memperoleh nilai peluang Pi kembali, peneliti dapat mengembalikan perhitungan atas fungsi invers pada persamaan awal (Zi dengan fungsi invers).
Meskipun uraian di atas lumayan kompleks dengan adanya penurunan model persamaan matematis (pencarian nilai Zi dari nilai peluangnya), akan tetapi bagi peneliti sangat diperlukan dalam proses pemahaman untuk menghasilkan data mentah (raw data) untuk digunakan dalam proses perhitungan dan pembentukan model probit. Oleh karenanya, peneliti dituntut untuk memahami segala bentuk notasi dan pemaknaan arti serta prosesnya sehingga pada tahapan selanjutnya dapat memudahkan peneliti dalam penerapan data baik kepada rumus maupun penggunaan software pendukung (misal : SPSS) dalam pembentukan model probit.
Pada kesempatan lainnya kita akan coba secara alplikatif menggunakan software SPSS untuk mencari model peluang linear, model logit dan model probit yang diaplikasi pada data riil penelitian. Agar dapat membantu peneliti secara sederhana mengaplikasikan pemahaman terori kepada data yang dimilikinya. SEMANGAT MEMPELAJARI!!!
Sumber Buku : Dr. Ir. Vincent Gaspersz, M.Sc.
Berikut ini akan saya berikan contoh riset keuangan menggunakan analisis Probit
-
Siswa harusTandai selesai
Regresi probit merupakan salah satu model regresi yang dapat menjelaskan hubungan antara variabel dependen kualitatif (kategorik) berdistribusi normal dan Bernoulli dan variabel independen kualitatif, kuantitatif, atau gabungan kualitatif dan kuantitatif.
Adapun untuk tutorial pegolahan analisis regresi Probit, silahkan anda lihat pada PPT sbb:
-
Siswa harusTandai selesai
1. Analisis Regresi Logit
Diketahui pada link google drive data SPSS (SAV) sbb:
https://drive.google.com/file/d/1ap2QDG7OgL9XCXJMLKeHsP6d81TjWYMA/view?usp=sharing
2. Analisis Regresi Probit
https://drive.google.com/file/d/1Vygsji40iDSFtiDedhfZMqP-mmKD5lFQ/view?usp=sharing
Silahkan anda: Analisis dan intepretasi hasilnya
-