Garis besar topik
-
-
Siswa harusTandai selesai
Assalamualikum Wr Wb... Syalom... Tamo Budaya.. Om Swastiastu... Tabik Pun.....
Apa kabar semuanya... semoga dalam keadaan sehat semua yach... masih stay at home ya...
minggu2 ini adalah minggu yg padat kalian akan mk pratikum aplikasi statistik.. kenapa ??? karena saya akan banyak tugas yang akan kalian kerjakan sehingga butuh waktu dan tenaga yang banyak... woww... kenapa demikian karena biar kalian nanti paham cara ngerjain skripseweet hehehhe di MK ini adalah inti di BAB IV kalian ngerjaian skripsi nanti.,
Semangat ya.. masih pake LMS kalian wajib dan kudu sering latihan yach.. percuma hanya dilihat aja tuh modul oke...Wassalam.....
-
-
Siswa harusTandai selesai
SPSS merupakan salah satu program statistik yang paling populer di antara program lainnya. SPSS banyak digunakan dalam pengolahan data untuk penelitian/riset. Program SPSS for Windows pada umumnya digunakan untuk memecahkan suatu permasalahan riset atau bisnis dalam hal statistika atau manajemen data, khususnya dalam penelitian dan analisis. Cara kerjanya adalah dengan membandingkan suatu data ke dalam suatu paket analisis. Keunggulan SPSS antara lain lebih mudah dalam penggunaan dan mudah dipahami. Selain itu SPSS merupakan suatu bagian intergal tentang proses analisis,menyediakan kemampuan untuk akses data, persiapan dan manajemen data, analisis data,serta dalam hal pelaporan. Perangkat lunak pengolahan data yang beredar saat ini sudah banyak macamnya, antara lain AMOS, Lisrel, Minitab,SPSS, Statistica, dll. SPSS merupakan perangkat lunak yang paling populer digunakan. SPSS memiliki berbagai kelebihan, yaitu terdapat banyak fasilitas yang dapat menangani berbagai persoalan statistika, tampilan user friendly, dan merupakan terobosan baru berkaitan dengan perkembangan teknologi informasi, khususnya E-Business. Dalam hal ini SPSS telah dilengkapi dengan fasilitas OLAP (Online Analytical Processing) yang akan memudahkan dalam pemecahan pengolahan data. Selain itu kelebihan SPSS adalah dapat digunakan untuk mengakses data dari perangkat lunak lain yang selanjutnya diolah dan kemudian dianalisis.
SEJARAH SPSS
SPSS merupakan singkatan dari Statistical Package for Social Science. Walaupun sekarang singkatannya menjadi Statistical Product and Service Solution, karena fungsinya yang lebih berkembang. SPSS pertama kali dikembangkan sekitar tahun 1960 sebagai perangkat lunak untuk sistem statistik pada komputer Mainframe oleh Norman H. Nie, C. Hadly, dan Dale Bent dari Stanford University. Pada tahun 1984 dikeluarkan SPSS/PC+ untuk personalkomputer (PC), sedangkan untuk versi Windows diliris pada tahun 1992. Sesuai perkembangannya dari tahun 1994 sampai 1999, beberapa produk yang telah dikeluarkan oleh SPSS, yaitu BMDP Statistical software, jandel ScientificSoftware, Clear Software, In2itive Technologies AS, Intergal Solution Ltd, dan Vento Software.SPSS memiliki berbagai macam versi untuk komputer Windows, MacOS, dan UNIX. Namun perkembangan SPSS lebih fokus pada platform Windows. Perkembangan dan penjualan produk SPSS dikendalikan oleh perusahaan SPSS.Inc. SPSS kini banyak digunakan untuk memberikan solusi analisis atas keinginan pelanggan agar dapat melakukan prediksi statistik. SPSS bisa memberikan solusi dalam berbagai bidang, seperti telekomunikasi, kesehatan, perbankan, sektor publik, dan barang-barang konsuntif. Dalam hal ini SPSS sangat membantu dalam memberikan analisis dan informasi yang dibutuhkan dengan proses pengolahan data yang lebih praktis dan tampilan visual pada outputnya.
Menu-menu seperti File, Edit, View, Windows dan Help adalah menu-menu umum yang sama dengan aplikasi under Windows lainnya. Menu-menu yang khas di SPSS adalah:
 Data, merupakan menu untuk memodifikasi data secara keseluruhan
seperti mengurutkan data, menggabungkan data dll. Transform, yaitu menu untuk mentranformasikan data berdasar kriteria
tertentu seperti penjumlahan antar variabel, recoding, dll. Analyze, menu untuk mengolah data seperti korelasi, regresi,
uji-t, dll. Graph, menu untuk memvisualisasikan data seperti histogram, scatter-plot,
boxplot dll. Utillities, menu pendukung yang berisi: informasi variabel, informasi
file, menu editor dll.
Data, merupakan menu untuk memodifikasi data secara keseluruhan
seperti mengurutkan data, menggabungkan data dll. Transform, yaitu menu untuk mentranformasikan data berdasar kriteria
tertentu seperti penjumlahan antar variabel, recoding, dll. Analyze, menu untuk mengolah data seperti korelasi, regresi,
uji-t, dll. Graph, menu untuk memvisualisasikan data seperti histogram, scatter-plot,
boxplot dll. Utillities, menu pendukung yang berisi: informasi variabel, informasi
file, menu editor dll.Menu yang tersedia dalam variabel view diantaranya:
1. Name
Kolom ini untuk memberi nama variabel. Nama variabel yang kita tuliskan disini akan muncul pada data editor. Pemberian nama harus diawali dengan huruf, tidak bisa dimulai dengan angka.
2. Type
Untuk menyesuaikan jenis data yang di masukkan, apakah numeric, string (data nominal yang berupa huruf). Klik ikon dalam kolom type maka akan muncul kotak dialog variabel type untuk melakukan perubahan tertentu.
3. Width
Digunakan untuk menentukan jarak/lebar kolom
4. Decimal
Digunakan untuk memasukkan angka-angka yang berupa koma (decimal)
5. Label
Kolom ini berfungsi untuk memberi label pada variabel yang kita inginkan. Misalnya kita mempunyai variabel ΓÇ£namaΓÇ¥ pada kolom pertama, variable tersebut bisa kita beri label ΓÇ£nama respondenΓÇ¥. Contoh lainnya bila kita mempunyai variabel dengan nama ΓÇ£skala1ΓÇ¥, kita bisa mendefinisikan lebih jelas dengan memberi label sesuai dengan nama skala kita sebenarnya, misalnya ΓÇ£skala kecemasanΓÇ¥ dll. Pemberian label ini sangat penting karena pada hasil analisis (output) akan tercetak label yang telah kita definisikan ini. Tercetaknya label pada output akan sangat membantu dalam interpetasi output tersebut.
6. Value
Kolom ini berfungsi untuk medefinisikan value data dari variabel yang dimaksud. Pemberian value ini biasanya untuk data yang bersifat ordinal dan interval. Klik ikon pada kolom value maka akan muncul kotak dialog value labels.
7. Missing
Kolom ini berfungsi untuk mendefinisikan missing value yang ada dalam data kita, yang dimaksud missing value disini adalah jika ada data kosong dalam data. Data kosong bisa disebabkan karena tidak tersedianya data atau sebab lain misanya pada pengisian skala ada item-item yang terlewat oleh responden.
8. Coloumn
Fungsi menu ini adalah untuk mengubah jumlah karakter yang dapat dimasukkan pada suatu variabel tertentu. Bila kita mengisi coloumn dengan angka 2 maka hanya dua digit data saja yang dapat dimasukkan pada variabel tersebut.
9. Align
Menu ini mengatur posisi data pada tiap cell. Pilihan posisinya ada tiga yaitu left, right dan center.
10. Measure
Menu ini mendefinisikan jenis data apa yang kita punyai. Pilihan yang ada adalah scale, nominal dan ordinal.
-
Siswa harusTandai selesai
Kalian Wajib Nonton Video ini dan Aplikasikan Ke Program SPSS mengenal fungsi item2 yang ada di SPSS
-
-
-
Siswa harusTandai selesai
Melakukan pengukuran terhadap sesuatu yang belum pernah dilakukan dapat ditempuh dengan cara membuat instrumen pengukuran. Apakah instrumen tersebut berbentuk kuisioner atau sesuatu bersifat fisik. Pada materi ini akan dibahas pengujian yang berkaitan dengan instrumen kuisioner yang terdiri dari bagian pengujian validitas dan reliabilitas.
Tingkat Kepercayaan Penelitian ada 3 yaitu sebagai berikut :
- 99 % dengan tingkat error (α =0,01) à Bidang Kedokteran
- 95 % dengan tingkat error (α =0,05) à Bidang sosial dan Ekonomi biasanya riset yang sifat penelitiannya tidak konsisten
- 90% dengan tingkat error (α =0,10) à Bidang riset yang masih baru atau disertasi penelitian
Sesuatu dikatakan valid jika alat ukur yang dibuat sesuai dengan apa yang hendak diukur, jika yang diukur adalah panjang, maka penggaris dapat dikatakan sebuah alat ukur yang valid. Akan tetapi bagaimana jika yang akan diukur adalah variabel kinerja. Kinerja yang terjadi pada seseorang manajer tentu berbeda dengan kinerja yang terjadi pada seorang cleaning service. Artiya jika obyek yang akan diteliti adalah berbeda akan tetapi variabel yang akan diangkat adalah sama, maka secara operasional akan terjadi perbedaan dalam mengukur indikasi-indikasi yang ada. Artinya akan muncul pertanyaan-pertanyaan yang berbeda pula. Pada bagian ini akan dibahas secara teknik proses pengujian validitas yang ada dalam kuisoner.
Tujuan dilakukannya uji validitas instrumen/angket yaitu untuk membuktikan apakah angket tesebut memiliki tingkat valid dari suatu pertanyaan penelitian, maka sebelum instrumen tersebut digunakan maka perlu di uji coba dan hasilnya di analisis (Sudarmanto, 2013).
Alat ukur yang digunakan adalah teknik korelasi Product Moment dari Pearson dan correlation matrixs.
Syarat Uji Validitas
Menurut Ghozali (2011) Pertanyaan didalam instrumen/angket dikatakan Valid apabila : rhitung > rtabel atau nilai signifikan (Sig.) < ╬▒ = 0,05. Sebaliknya, Tidak Valid apabila, rhitung < rtabel atau nilai signifikan (Sig.) > ╬▒ = 0,05.
-
Siswa harusTandai selesai
Kalian Wajib Belajar dulu ya guys,,,, Cara Menginput Data okeee..
Gunakan Aplikasi SPSS Ver 22 or 23 -
Siswa harusTandai selesai
Guys ini Latihan yach... Untuk Input data Kusioner yang di uji menggunakan validitas cara 1. terus kalian latihan yach seperti yang dimodul
-
-
-
-
Siswa harusTandai selesai
Langkah-langkah Uji Validitas dengan Cara Correlation Matrix
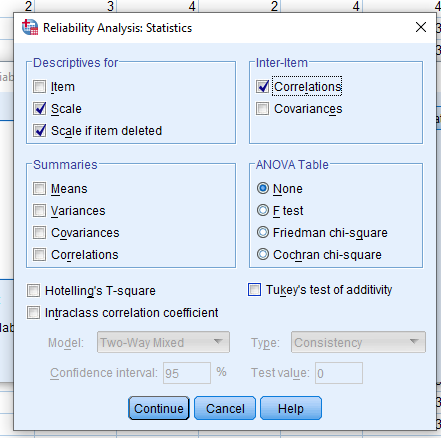
Pada postingan sebelumnya yang berjudul Langkah-langkah uji validitas dengan korelasi product moment selanjutnya kita akan mencoba melakukan uji validitas dengan cara correlation matrix. Masih dengan data yang sama Langkah-langkah uji validitas dengan korelasi product moment berikut adalah langkah-langkah melakukan uji validitas dengan Correlation Matrix:- Klik Analyze lalu pilih Scale selanjutnya Reliability Analysis kemudian pindahkan seluruh data ke kolom items lalu pilih statistics, ceklist Scale, scale if item deleted dan ceklis Correlation dalam kolom inter-items kemudian OK (Lihat gambar)


 Untuk mengetahui apakah Item pertanyaan yang kita gunakan dalam angket penelitian valid atau tidaknya bisa melihat tabel item total statistic pada output Spss berikut ini:
Untuk mengetahui apakah Item pertanyaan yang kita gunakan dalam angket penelitian valid atau tidaknya bisa melihat tabel item total statistic pada output Spss berikut ini: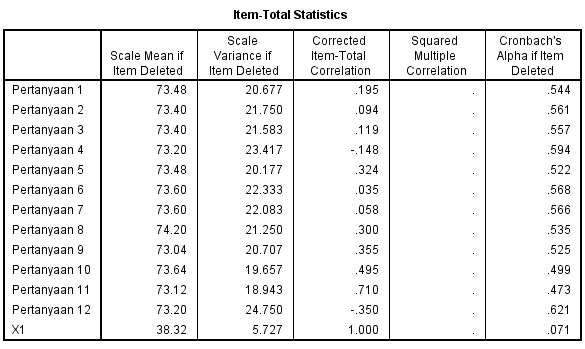 Lihat pada kolom Corrected item-total correlation dimana syarat data valid jika Nilai rhitung>rtabel. Dengan jumlah Sampel sebanyak 25 diperoleh rtabel (25-2=0,336). Berikut interprestasinya
Lihat pada kolom Corrected item-total correlation dimana syarat data valid jika Nilai rhitung>rtabel. Dengan jumlah Sampel sebanyak 25 diperoleh rtabel (25-2=0,336). Berikut interprestasinya- Item pertanyaan 1 memiliki nilai rhitung 0,195<0,336 maka dapat disimpulkan item pertanyaan 1 tidak valid
- Item pertanyaan 2 memiliki nilai rhitung 0,094<0,336 maka dapat disimpulkan item pertanyaan 2 tidak valid
- Item pertanyaan 3 memiliki nilai rhitug 0,119<0,336 maka dapat simpulkan item pertanyaan 3 tidak valid
- Item pertanyaan 4 memiliki nilai rhitug 0,148<0,336 maka dapat simpulkan item pertanyaan 4 tidak valid
- Item pertanyaan 5 memiliki nilai rhitug 0,324<0,336 maka dapat simpulkan item pertanyaan 5 tidak valid.
- Item pertanyaan 6 memiliki nilai rhitug 0,035<0,336 maka dapat simpulkan item pertanyaan 6 tidak valid.
- Item pertanyaan 7 memiliki nilai rhitug 0,058<0,336 maka dapat simpulkan item pertanyaan 7 tidak valid.
- Item pertanyaan 8 memiliki nilai rhitug 0,300>0,336 maka dapat simpulkan item pertanyaan 3 valid.
- Item pertanyaan 9 memiliki nilai rhitug 0,355>0,336 maka dapat simpulkan item pertanyaan 3 valid.
- Item pertanyaan 3 memiliki nilai rhitug 0,495>0,336 maka dapat simpulkan item pertanyaan 3 valid.
- Item pertanyaan 3 memiliki nilai rhitug 0,710>0,336 maka dapat simpulkan item pertanyaan 3 valid
- Item pertanyaan 3 memiliki nilai rhitug 0,350<0,336 maka dapat simpulkan item pertanyaan 3 valid
-
Siswa harusTandai selesai
Please dipahami yach cara proses belajarnya....
-
-
-
Siswa harusTandai selesai
Beberapa item yang mengelompok menjadi indikasi sebuah variabel tidak cukup dilihat dari ukuran validitas saja, namun juga diukur besarnya kehandalan yang terjadi pada kelompok tersebut. Sama hal dengan uji validitas untuk mengukur reliabilitas sebuah instrumen dapat digunakan beberapa metode seperti split half, alpha Cronbach, Test Retest, Rulon, Hyot, dan banyak lagi lainnya.
ΓÇó Reliabilitas intrumen menggambarkan kemantapan dan kestabilan alat ukur yang digunakan oleh penelitian.
ΓÇó Suatu instrumen penelitian dikatakan memiliki relibilitas yang tinggi atau baik apabila instrumen penelitian selalu memberikan hasil yang sama ketika digunakan berkali-kali, baik oleh peneliti yang sama maupun peneliti yang berbeda.
Metode Dalam Mengukur Reliabilitas
Menurut R. Gunawan Sudarmanto (2013) menyatakan ada 2 cara dalam mengukur reliabilitas yaitu :
- Metode Pengulangan (Test ΓÇô Retest Method)
- Metode Belah Dua (Split-Half Method)
Syarat Relibilitas adalah sebagi berikut :
Pertanyaan didalam instrumen/angket dikatakan Reliabel apabila : rhitung > rtabel atau nilai signifikan (Sig.) < ╬▒ = 0,05. sebaliknya, Tidak Reliabel apabila, rhitung < rtabel atau nilai signifikan (Sig.) > ╬▒ = 0,05.
A. Metode Pengulangan (Test ΓÇô Retest Method)
Metode pengulangan berarti peneliti harus melakukan beberapa kali tes, minimum dua kali tes dengan waktu yang berbeda à tujuannya untuk mengetahui kestabilan dalam suatu instrumen penelitian. Bisa juga metode ini menggunakan pilot t-tes dimana angket di uji coba oleh tenaga profesional yang sesuai dengan bidang risetnya.
Langkah mengerjakan Metode cara 1 :
Klik Analyze - Correlate - Bevariate - Pindahkan semua Variabel kekolom Variabels - Ceklis Person - Ceklis two tailed/one tailde - Ceklis Flag Significant Corelations - ok
-
-
-
Siswa harusTandai selesai
Cara Uji Reliabilitas Split-half Spearman Brown dengan SPSS Lengkap
Reliabilitas Split-half Spearman Brown dengan SPSS Lengkap | Validitas dan reliabilitas merupakan persyaratan utama sebuah instrumen dikatakan ampuh sebagai alat pengumpul data penelitian. Sebuah instrumen dapat dikatakan valid apabila mampu mengukur apa yang hendak di ukur. Sementara, sebuah instrumen dikatakan reliabel jika memiliki kestabilan atau konsistensi untuk mengukur sesuatu yang sama dalam berbagai waktu.

Instrumen reliabel berarti instrumen tersebut dapat dipercaya dan diandalkan sebagai alat pengumpul data yang baik. Walaupun instrumen tersebut digunakan berulang kali dalam penelitian hasilnya akan tetap sama atau konsisten. Ada beberapa cara atau teknik yang dapat digunakan untuk mengukur reliabilitas sebuah instrumen, antara lain: melakukan tes ulang, melakukan tes paralel, melakukan uji cronbach alpha, dan uji split half (belah dua). Sementara itu, pengujian reliabilitas dapat dilakukan secara bersamaan (gabungan) untuk seluruh butir instrumen pervariabel, maupun dilakukan secara sendiri-sendiri perbutir soal.
Uji reliabilitas metode split-half spearman brown, pada prinsipnya dilakukan dengan cara membagi dua (belah dua) butir-butir soal instrumen pervariabel lalu menghubungkan belah dua tersebut dengan menggunakan rumus korelasi spearman brown. Jika hasil analisis korelasinya ≥ 0,80, maka instrumen penelitian dinyatakan reliabel (Jonathan Sarwono, 2015: 249).
Contoh Kasus Uji Reliabilitas Split-half Spearman Brown
Contoh yang saya pakai dalam panduan ini, menggunakan kasus pada artikel sebelumnya (Cara Uji Validitas Kuesioner Teknik Corrected Item Total Correlation dengan SPSS). Dalam artikel tersebut kita telah melakukan uji validitas dan mendapatkan kesimpulan bahwa seluruh butir soal kuesioner untuk variabel kompetensi (X) dinyatakan valid (syarat melakukan uji reliabilitas adalah butir soal valid). Selanjutnya kita akan melakukan uji reliabilitas split-half spearman brown dengan SPSS. Adapun langkah-langkah pengujiannya adalah sebagai berikut.
Cara Uji Reliabilitas Split-half Spearman Brown dengan SPSS
1. Buka file data SPSS bernama ΓÇ£Untitled Validitas Corrected Item Total Correlation [www.spssindonesia.com].savΓÇ¥ yang sebelumnya telah anda download. Jika belum punya, maka anda dapat mendownloadnya sekarang melalui link [Download Data]. Tampak di layar Data View
2. Setelah itu, klik menu Analyze – Scale – Reliability Analysis…
3. Maka mucul dialog “Reliability Analysis”, selanjutnya pindahkan butir soal X.1 sampai dengan butir soal X.8 ke kotak Items (keterangan: kita akan melakukan uji reliabilitas butir kuesoner untuk variabel kompetensi). Pada bagian “Model” pilih Split-half, lalu klik Statistics…
4. Maka muncul diloag ΓÇ£Reliability Analysis: StatisticsΓÇ¥, kemudian pada bagian ΓÇ£Descriptives forΓÇ¥ berikan tanda ceklist (V) untuk Scale if item deleted, selanjutnya klik Continue. Tampak di layar.
5. Terakhir klik Ok, maka muncul output SPSS berjudul ΓÇ£ReliabilityΓÇ¥, berikutnya kita tinggal melakukan penafsiran atas hasil output tersebut.
Interpretasi Output Uji Reliabilitas Split-half Spearman Brown dengan SPSS
Tabel output pertama ΓÇ£Case Processing SummaryΓÇ¥
Berdasarkan tabel output di atas diketahui jumlah sampel (N) adalah 20 orang karyawan, sehingga valid 100%. Sementara nilai Excluded adalah 0 artinya tidak ada data yang dikecualikan atau semua data digunakan.
Tabel output kedua ΓÇ£Reliability StatisticsΓÇ¥
Tabel output di atas memberikan informasi mengenai relibilitas (kehandalan) butir soal secara keseluruhan (gabungan) pada variabel kompetensi (X). Berdasarkan tabel output di atas diketahui nilai korelasi Guttman Split-Half Coefficient adalah sebesar 0,818 > 0,80, dengan demikian maka dapat disimpulkan bahwa butir soal untuk variabel kompetensi (X) secara keseluruhan (gabungan) dinyatakan reliabel.
Catatan: Keterangan yang terdapat di bawah tabel output ΓÇ£Reliability StatisticsΓÇ¥, menunjukkan bentuk belah dua butir kuesioner variabel kompetensi. Dengan kata lain analisis korelasi spearman brown dipakai untuk hubungan antara butir soal nomor X.1, X.2, X.3, X.4 (belah pertama) dengan butir soal nomor X.5, X.6, X.7, X.8 (belah kedua).
Tabel output ketiga ΓÇ£Item-Total StatisticsΓÇ¥
Untuk mengetahui apakah butir-butir soal kuesioner variabel kompetensi tersebut reliabel atau tidak, maka kita cukup memperhatikan nilai yang ada dalam tabel “Cronbach's Alpha if Item Deleted”. Menurut Jonathan Sarwono (2015: 262) butir pertanyaan dikatakan reliabel jika nilai Cronbach's Alpha if Item Deleted ≥ 0,80. Berdasarkan tabel output “Item-Total Statistics” diketahui nilai Cronbach's Alpha if Item Deleted untuk seluruh (8) butir soal > 0,80, dengan demikian maka dapat disimpulkan bahwa butir-butir soal untuk variabel kompetensi (X) dinyatakan reliabel.
Informasi tambahan: Menurut Dr. Riduwan, dkk (2014: 200), Butir pertanyaan kuesioner dikatakan reliabel jika nilai Guttman Split-Half Coefficient > r tabel product momentΓÇ¥.
Terkait perbedaan pendapat di kalangan ahli atau pakar mengenai dasar pengambilan keputusan dalam uji reliabilitas ini, kita tidak perlu mempersoalkannya terlalu jauh. Sebab perbedaan pandangan adalah sesuatu yang wajar. Oleh karena itu sebagai peneliti kita cukup merujuk pada salah satu pendapat ahli tersebut. Khusus penelitian untuk skripsi maupun tesis ada baiknya kita mengkonsultasikan persoalan ini dengan dosen pembimbing dan meminta persetujuan untuk menggunakan teori dari ahli yang mana.
-
-
-
Siswa harusTandai selesai
STATISTIK DESKRIPTIF (DESCRIPTIVE STATISTICS)
Merupakan bidang ilmu statistik yang mempelajari cara-cara pengumpulan, penyusunan dan penyajian data suatu penelitian. Kegiatan yang termasuk dalam kategori ini adalah kegiatan pengumpulan data, pengelompokan data, penentuan nilai dan fungsi statistik, pembuatan grafik, diagram dan gambar. Statistika deskriptif adalah ilmu yang digunakan untuk menganalisa data dengan melihat gambaran dari data tersebut. Gambaran suatu data dapat dilihat dari:
1. Besaran statistik, misal nilai mean (rata-rata), Standar deviasi (simpangan baku), variansi, modus dan sebagainya.
2. Grafik dari data
Fungsi analisis deskriptif adalah untuk memberikan gambaran umum tentang data yang telah diperoleh. Gambaran umum ini bisa menjadi acuan untuk melihat karakteristik data yang kita peroleh. Analisis deskriptif sering diabaikan penggunaannya dalam penelitian-penelitian sosial, karena memang dalam beberapa fungsi analisis lainnya otomatis tercantum analisis deskriptif.
Dalam SPSS, metode statistic deskriftif dapat dilakukan dengan menu Descriptive Statistics yang terdiri atas :
- Frequency , digunakan untuk menyusun data yang jumlahnya relative banyak kedalam suatu table frekwensi.
- Descriptives, digunakan untuk menampilkan deskripsi statistik univariat dan dari variable numeric yang didaftar.
- Explore, digunakan untuk mengolah data statistic yang semakin kompleks dan dilengkapi dengan pengujian kenormalan sebuah data.
- Crosstab, digunakan untuk menampilkan dalam bentuk tabulasi silang
-
-
-
Siswa harusTandai selesai
Banyak sekali teknik pengujian normalitas suatu distribusi data yang telah dikembangkan oleh para ahli. Kita sebenarnya sangat beruntung karena tidak perlu mencari-cari cara untuk menguji normalitas, dan bahkan saat ini sudah tersedia banyak sekali alat bantu berupa program statistik yang tinggal pakai. Berikut adalah salah satu pengujian normalitas dengan menggunakan teknik Kolmogorov Smirnov.
Pengertian Uji Kolmogorov Smirnov
Uji Kolmogorov Smirnov adalah pengujian normalitas yang banyak dipakai, terutama setelah adanya banyak program statistik yang beredar. Kelebihan dari uji ini adalah sederhana dan tidak menimbulkan perbedaan persepsi di antara satu pengamat dengan pengamat yang lain, yang sering terjadi pada uji normalitas dengan menggunakan grafik.
Konsep Uji Kolmogorov Smirnov
Konsep dasar dari uji normalitas Kolmogorov Smirnov adalah dengan membandingkan distribusi data (yang akan diuji normalitasnya) dengan distribusi normal baku. Distribusi normal baku adalah data yang telah ditransformasikan ke dalam bentuk Z-Score dan diasumsikan normal. Jadi sebenarnya uji Kolmogorov Smirnov adalah uji beda antara data yang diuji normalitasnya dengan data normal baku.
Seperti pada uji beda biasa, jika signifikansi di bawah 0,05 berarti terdapat perbedaan yang signifikan, dan jika signifikansi di atas 0,05 maka tidak terjadi perbedaan yang signifikan. Penerapan pada uji Kolmogorov Smirnov adalah bahwa jika signifikansi di bawah 0,05 berarti data yang akan diuji mempunyai perbedaan yang signifikan dengan data normal baku, berarti data tersebut tidak normal.
Signifikansi Uji Kolmogorov
Lebih lanjut, jika signifikansi di atas 0,05 maka berarti tidak terdapat perbedaan yang signifikan antara data yang akan diuji dengan data normal baku, artinya, ya. Berarti data yang kita uji normal, kan tidak berbeda dengan normal baku.
Jika kesimpulan kita memberikan hasil yang tidak normal, maka kita tidak bisa menentukan transformasi seperti apa yang harus kita gunakan untuk normalisasi. Jadi ya kalau tidak normal, gunakan plot grafik untuk melihat menceng ke kanan atau ke kiri. Atau menggunakan Skewness dan Kurtosis sehingga dapat ditentukan transformasi seperti apa yang paling tepat dipergunakan.
Uji Normalitas dengan Kolmogorov Smirnov dengan Program SPSS
Pengujian normalitas dengan menggunakan Program SPSS dilakukan dengan menu Analyze, kemudian klik pada Nonparametric Test, lalu klik Legacy Dialogs, Klik 1-Sample K-S. K-S itu singkatan dari Kolmogorov-Smirnov. Maka akan muncul kotak One-Sample Kolmogorov-Smirnov Test.
-
-
-
-
Siswa harusTandai selesai
1. Uji Multikolinearitas
Menurut Ghozali (2016) pada pengujian multikolinearitas bertujuan untuk mengetahui apakah model regresi ditemukan adanya korelasi antar variabel independent atau variable bebas. Efek dari multikolinearitas ini adalah menyebabkan tingginya variabel pada sampel. Hal tersebut berarti standar error besar, akibatnya ketika koefisien diuji, t-hitung akan bernilai kecil dari t-tabel. Hal ini menunjukkan tidak adanya hubungan linear antara variabel independen yang dipengaruhi dengan variabel dependen.
Untuk menemukan terdapat atau tidaknya multikolinearitas pada model regresi dapat diketahui dari nilai toleransi dan nilai variance inflation factor (VIF). Nilai Tolerance mengukur variabilitas dari variabel bebas yang terpilih yang tidak dapat dijelaskan oleh variabel bebas lainnya. Jadi nilai tolerance rendah sama dengan nilai VIF tinggi, dikarenakan VIF = 1/tolerance, dan menunjukkan terdapat kolinearitas yang tinggi. Nilai cut off yang digunakan adalah untuk nilai tolerance 0,10 atau nilai VIF diatas angka 10.
2. Uji Heteroskedastisitas
Uji ini bertujuan untuk melakukan uji apakah pada sebuah model regresi terjadi ketidaknyamanan varian dari residual dalam satu pengamatan ke pengamatan lainnya. Apabila varian berbeda, disebut heteroskedastisitas. Salah satu cara untuk mengetahui ada tidaknya heteroskedastisitas pada suatu model regresi linier berganda, yaitu dengan melihat grafik scatterplot atau dari nilai prediksi variabel terikat yaitu SRESID dengan residual error yaitu ZPRED. Apabila tidak terdapat pola tertentu dan tidak menyebar diatas maupun dibawah angka nol pada sumbu y, maka dapat disimpulkan tidak terjadi heteroskedastisitas. Untuk model penelitian yang baik adalah yang tidak terdapat heteroskedastisitas (Ghozali, 2016).
3. Uji Autokorelasi
Menurut Ghozali (2016) autokorelasi dapat muncul karena observasi yang berurutan sepanjang waktu yang berkaitan satu sama lainnya. Permasalahan ini muncul karena residual tidak bebas pada satu observasi ke observasi lainnya. Untuk model regresi yang baik adalah pada model regresi yang bebas dari autokolerasi. Untuk mendeteksi terdapat atau tidaknya autokorelasi adalah dengan melakukan uji Run Test.
Run test merupakan bagian dari statistik non-parametik yang dapat digunakan untuk melakukan pengujian, apakah antar residual terjadi korelasi yang tinggi. Apabila antar residual tidak terdapat hubungan korelasi, dapat dikatakan bahwa residual adalah random atau acak. Dengan hipotesis sebagai dasar pengambilan keputusan adalah sebagai berikut (Ghozali, 2016):
Apabila nilai Asymp. Sig. (2-tailed) kurang dari 5% atau 0,05, maka untuk H0 ditolak dan Ha diterima. Hal tersebut berarti data residual terjadi secara tidak acak (sistematis).
Apabila nilai Asymp. Sig. (2-tailed) lebih dari 5% atau 0,05, maka untuk H0 diterima dan Ha ditolak. Hal tersebut berarti data residual terjadi secara acak (random).
-
-
-
-
Tugas Regresi Klasik Penugasan
Please dikerjakan tugasnya yach....
-
-
-
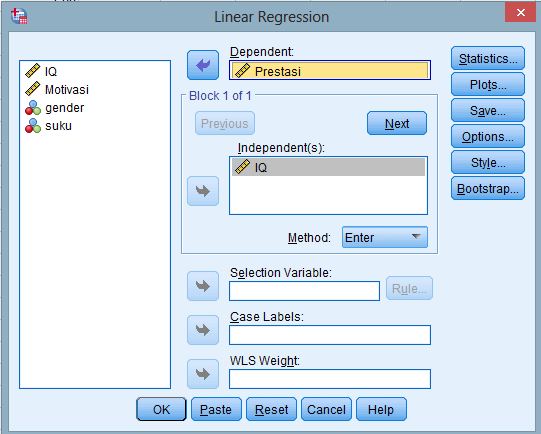
Siswa harusTandai selesaiKoefien korelasi hanya mampu menggambarkan kuat lemahnya hubungan dua variabel, namun tidak mampu menjelaskan hubungan funsional variabel mana yang menjadi sebab dan variabel mana yang menjadi akibat. Analisis regresi mempelajari bentuk hubungan antara satu atau lebih variabel bebas (X) dengan satu variabel tergantung (Y). Oleh karena itu, secara umum dapat dikatakan analisis regresi merupakan kelanjutan dari analisis korelasi karena dapat menentukan daya prediksi perubahan variabel Y akibat perubahan variabel X. Untuk dapat melakukan analisis regresi, data kita minimal harus berada pada level interval dan terdistribusi normal. Untuk menguji asumsi normalitas, dapat dilihat di sini.Analisis Regresi TunggalJika analisis dilakukan pada satu variabel dependen dan satu variabel independen, maka kita gunakan analisis regresi tunggal. Berikut ini adalah contoh kasus analisis regresi tunggal. Data untuk melakukan latihan analisis dapat didownload di siniContoh kasusVariabel X : IQVariabel Y : PrestasiHipotesis : IQ berperan sebagai prediktor prestasiAnalisis dengan SPSS1. Klik Analyze ΓÇô regression ΓÇô linear2. Masukkan prestasi ke kolom dependent, serta IQ ke kolom independent3. Klik OK
 Berikut adalah output hasilnya
Berikut adalah output hasilnya Dari hasil di atas nilai R square adalah 0,322. Hal ini menunjukkan bahwa 32,2% variasi prestasi dapat dijelaskan oleh variasi IQ. Standar Error adalah 3,05. Semakin kecil standar error semakin tepat dalam memprediksi variabel tergantung.Dari uji ANOVA atau uji F didapat nilai F(1,79) sebesar 37,47 dengan p<0,01. Karena p<0,01 maka dapat dikatakan bahwa IQ dapat digunakan sebagai prediktor prestasi.Hasil uji t juga menunjukkan bahwa IQ mampu secara signifikan memprediksi prestasi (t=6,12; p<0,01) dengan ╬▓=0,567. Selain itu kita juga dapat menuliskan persamaan regresinya. Rumus umum persamaan regresi adalah Y = a + bX. Jika kita masukan nilainya, maka persamaan regresinya menjadi: Prestasi = 49,026 + 0,285 IQ. Hal ini menunjukkan jika seseorang tidak memiliki iq sama sekali, maka prestasinya adalah 49,026, sedangkan setiap satu poin kenaikan IQ anak menaikkan prestasi sebesar 0,285.Analisis Regresi BergandaAnalisis regresi berganda dilakukan jika ada lebih dari satu variabel independen dalam memprediksi satu variabel dependen. Misal kasusnya adalah sebagai berikutContoh kasusVariabel X1 : IQVariabel X2 : MotivasiVariabel Y : PrestasiHipotesis : IQ dan motivasi berperan sebagai prediktor prestasiAnalisis dengan SPSS1. Klik Analyze ΓÇô regression ΓÇô linear2. Masukkan prestasi ke kolom dependent, serta IQ dan motivasi ke kolom independent3. Klik statistics, centang R Square change, part and partial correlation, dan colinearity diagnosis4. Ganti metode ke stepwise, lalu OK
Dari hasil di atas nilai R square adalah 0,322. Hal ini menunjukkan bahwa 32,2% variasi prestasi dapat dijelaskan oleh variasi IQ. Standar Error adalah 3,05. Semakin kecil standar error semakin tepat dalam memprediksi variabel tergantung.Dari uji ANOVA atau uji F didapat nilai F(1,79) sebesar 37,47 dengan p<0,01. Karena p<0,01 maka dapat dikatakan bahwa IQ dapat digunakan sebagai prediktor prestasi.Hasil uji t juga menunjukkan bahwa IQ mampu secara signifikan memprediksi prestasi (t=6,12; p<0,01) dengan ╬▓=0,567. Selain itu kita juga dapat menuliskan persamaan regresinya. Rumus umum persamaan regresi adalah Y = a + bX. Jika kita masukan nilainya, maka persamaan regresinya menjadi: Prestasi = 49,026 + 0,285 IQ. Hal ini menunjukkan jika seseorang tidak memiliki iq sama sekali, maka prestasinya adalah 49,026, sedangkan setiap satu poin kenaikan IQ anak menaikkan prestasi sebesar 0,285.Analisis Regresi BergandaAnalisis regresi berganda dilakukan jika ada lebih dari satu variabel independen dalam memprediksi satu variabel dependen. Misal kasusnya adalah sebagai berikutContoh kasusVariabel X1 : IQVariabel X2 : MotivasiVariabel Y : PrestasiHipotesis : IQ dan motivasi berperan sebagai prediktor prestasiAnalisis dengan SPSS1. Klik Analyze ΓÇô regression ΓÇô linear2. Masukkan prestasi ke kolom dependent, serta IQ dan motivasi ke kolom independent3. Klik statistics, centang R Square change, part and partial correlation, dan colinearity diagnosis4. Ganti metode ke stepwise, lalu OK Berikut adalah output hasilnya
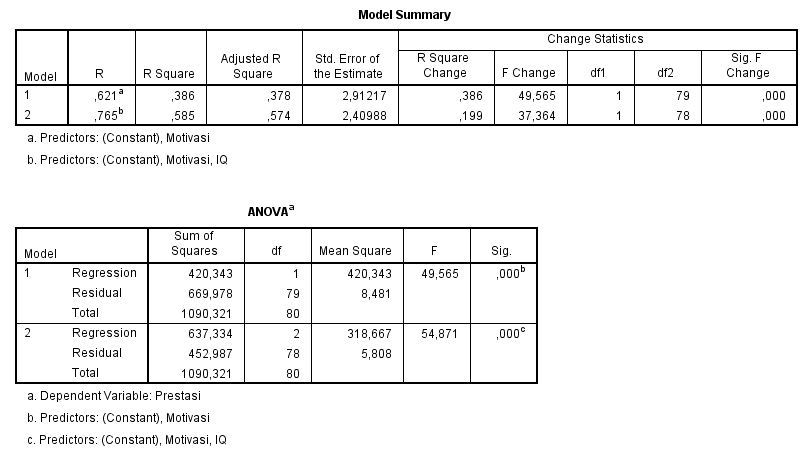
Berikut adalah output hasilnya Model summary menyajikan dua model. Model pertama hanya berisikan motivasi sebagai prediktor, sedangkan model kedua berisikan motivasi dan IQ sebagai prediktor. Hal ini karena kita memiliki metode stepwise. Metode stepwise akan melakukan analisis secara bertahap mulai dari prediktor yang hubungannya paling kuat dengan variabel dependen. Pada model 1 kita lihat bahwa R Square sebesar 0,386. Hal ini menunjukkan bahwa 38,6% variasi prestasi dapat dijelaskan oleh variasi motivasi. Pada model 2 kita lihat bahwa R Square sebesar 0,585. Hal ini menunjukkan bahwa 58,5% variasi prestasi dapat dijelaskan oleh variasi IQ dan motivasi. Artinya dengan penambahan IQ sebagai prediktor, variasi yang dapat dijelaskan naik sebesar 19,9%. Standar Error adalah 2,4. Semakin kecil standar error semakin tepat dalam memprediksi variabel tergantung.Dari uji Anova model 2 didapat nilai F(2,78) sebesar 54,87 dengan p<0,01. Karena p<0,01 maka dapat dikatakan bahwa IQ dan motivasi secara bersama-sama dapat digunakan sebagai prediktor prestasi.
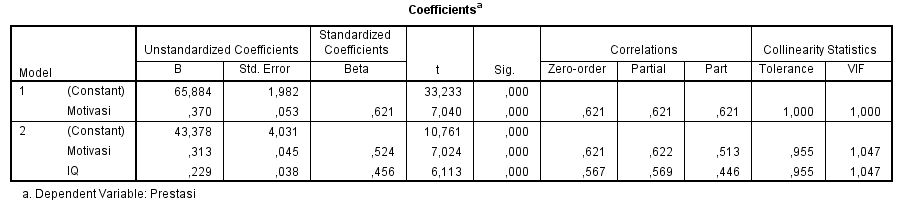
Model summary menyajikan dua model. Model pertama hanya berisikan motivasi sebagai prediktor, sedangkan model kedua berisikan motivasi dan IQ sebagai prediktor. Hal ini karena kita memiliki metode stepwise. Metode stepwise akan melakukan analisis secara bertahap mulai dari prediktor yang hubungannya paling kuat dengan variabel dependen. Pada model 1 kita lihat bahwa R Square sebesar 0,386. Hal ini menunjukkan bahwa 38,6% variasi prestasi dapat dijelaskan oleh variasi motivasi. Pada model 2 kita lihat bahwa R Square sebesar 0,585. Hal ini menunjukkan bahwa 58,5% variasi prestasi dapat dijelaskan oleh variasi IQ dan motivasi. Artinya dengan penambahan IQ sebagai prediktor, variasi yang dapat dijelaskan naik sebesar 19,9%. Standar Error adalah 2,4. Semakin kecil standar error semakin tepat dalam memprediksi variabel tergantung.Dari uji Anova model 2 didapat nilai F(2,78) sebesar 54,87 dengan p<0,01. Karena p<0,01 maka dapat dikatakan bahwa IQ dan motivasi secara bersama-sama dapat digunakan sebagai prediktor prestasi. Salah satu asumsi khusus untuk analisis regresi ganda adalah antar variabel independen korelasinya tidak boleh tinggi (asumsi multikolinearitas). Hal ini dapat dilihat pada nilai colinearity statistics pada kolom tolerance dan VIF. Nilai tolerance yang diizinkan adalah 0,1 sedangkan nilai VIF yang diizinkan adalah di bawah 10. Jika dua hal ini terpenuhi, maka asumsi multikolineritas terpenuhi. Dalam analisis ini nilai tolerance=0,95, sementara nilai VIF=1,04. Dengan demikian maka asumsi multikolineritas terpenuhi.Hasil uji t merupakan pern masing-masing variabel independen terhadap variabel dependen. Uti t pada model 2 menunjukkan bahwa motivasi mampu secara signifikan memprediksi prestasi (t=7,02; p<0,01) dengan ╬▓=0,524. Begitu pula dengan IQ yang juga secara signifikan mampu memprediksi prestasi (t=6,11; p<0,01) dengan ╬▓=0,456. Selain itu kita juga dapat menuliskan persamaan regresinya. Rumus umum persamaan regresi adalah Y = a + b1X1 + b2X2. Jika kita masukan nilainya, maka persamaan regresinya menjadi: Prestasi = 43,378 + 0,229*IQ + 0,313*motivasi. Hal ini menunjukkan jika seseorang tidak memiliki IQ dan motivasi sama sekali, maka prestasinya adalah 43,378, sedangkan setiap satu poin kenaikan IQ anak menaikkan prestasi sebesar 0,229 dan setiap satu poin kenaikan motivasi akan menaikan prestasi sebesar 0,313.Sumbangan efektif masing-masing variabel dapat dihitung dengan rumus ╬▓ x zero-order x 100%. Dengan demikian sumbangan efektif masing-masing variabel adalahIQ : 0,45 x 0,56 x 100% = 25,2%Motivasi : 0,54 x 0,62 x 100% = 33,4%Total dari sumbangan efektif kedua variabel ini akan sama dengan nilai R square yang sudah disebutkan di atas.
Salah satu asumsi khusus untuk analisis regresi ganda adalah antar variabel independen korelasinya tidak boleh tinggi (asumsi multikolinearitas). Hal ini dapat dilihat pada nilai colinearity statistics pada kolom tolerance dan VIF. Nilai tolerance yang diizinkan adalah 0,1 sedangkan nilai VIF yang diizinkan adalah di bawah 10. Jika dua hal ini terpenuhi, maka asumsi multikolineritas terpenuhi. Dalam analisis ini nilai tolerance=0,95, sementara nilai VIF=1,04. Dengan demikian maka asumsi multikolineritas terpenuhi.Hasil uji t merupakan pern masing-masing variabel independen terhadap variabel dependen. Uti t pada model 2 menunjukkan bahwa motivasi mampu secara signifikan memprediksi prestasi (t=7,02; p<0,01) dengan ╬▓=0,524. Begitu pula dengan IQ yang juga secara signifikan mampu memprediksi prestasi (t=6,11; p<0,01) dengan ╬▓=0,456. Selain itu kita juga dapat menuliskan persamaan regresinya. Rumus umum persamaan regresi adalah Y = a + b1X1 + b2X2. Jika kita masukan nilainya, maka persamaan regresinya menjadi: Prestasi = 43,378 + 0,229*IQ + 0,313*motivasi. Hal ini menunjukkan jika seseorang tidak memiliki IQ dan motivasi sama sekali, maka prestasinya adalah 43,378, sedangkan setiap satu poin kenaikan IQ anak menaikkan prestasi sebesar 0,229 dan setiap satu poin kenaikan motivasi akan menaikan prestasi sebesar 0,313.Sumbangan efektif masing-masing variabel dapat dihitung dengan rumus ╬▓ x zero-order x 100%. Dengan demikian sumbangan efektif masing-masing variabel adalahIQ : 0,45 x 0,56 x 100% = 25,2%Motivasi : 0,54 x 0,62 x 100% = 33,4%Total dari sumbangan efektif kedua variabel ini akan sama dengan nilai R square yang sudah disebutkan di atas. -
-
-
-
Tugas Uji Regresi Penugasan
Dikerjakan Tugasnya yach... semangat
-
-
-
-
-
SOAL UAS Penugasan
Kerjakan yach...Semangat
-