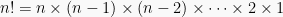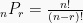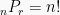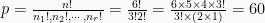Garis besar topik
-
-
Assalamu'alaikum Wr. Wb
Tabiik Puun…
Selamat datang Rekan Rekan Mahasiswa yang saya banggakan.
Dimanapun berada..., semoga selalu dalam keadaan sehat walafiat dan dalam Lindungan Allah SWT.Selamat datang di Mata kuliah Statistical and Data Analysis Pascasarjana Magister Teknologi Informatika (MTI) IBI Darmajaya. Mata kuliah ini ditujukan bagi peserta didik yang sedang mengambil program S2 Sarjana pada rumpun Ilmu Komputer, terutama terkait dengan bidang studi: Sistem Informasi, Sistem Komputer, dan Teknik Informatika
Mata Kuliah Statististcs and Data Analytics ini memiliki beban SKS sebesar 3 SKS, dengan kode Matakuliah : MTI193102
Selamat mengikuti perkuliahan ini dengan baik,
Salam hangat dan tetap semangat !!
Wassalamu'alaikum Wr. Wb
Dr. Faurani Santi Singagerda, SE, M.Sc, CFtP, CIQnR -
Siswa harusTandai selesai
Matakuliah ini memberikan pemahaman dan penguasaan mengenai konsep dasar statistika dan probabilitas, pencacahan titik contoh, distribusi probabilitas diskret, distribusi normal, distribusi sampling, pendugaan parameter, pengujian hipotesis parametrik dan non paramterik, analisis data dan penarikan kesimpulan serta visualisasi data.
Mata kuliah Statistika dan Analisis Data ini terbagi dalam 14 sesi pembelajaran di mana pada setiap sesi terbentuk pemahaman dan kompetensi yang kuat mengenai peluang bisnis dari teknolgi finansial. Mata kuliah ini juga dapat dipelajari dengan metode Self Paced.
-
Siswa harusTandai selesai
┬╖ Mahasiswa mampu menjelaskan konsep umum statistika serta serta mengidentifikasi skala data dari variable
┬╖ Mahasiswa mampu mempraktikkan penyajian data dengan cara tekstular, tabular, dan grafikal
┬╖ Mahasiswa mampu menyeleksi, menghitung dan mengolah data penelitian.
┬╖ Mahasiswa mampu memahami prosedur dalam penelitan, proses dan pengolahan data statistika
┬╖ Mahasiswa mampu memahami prosedur dalam pengujian suatu data statistik
* Mahasiswa mampu menganalisa hasil pengujian suatu data statistik
-
Siswa harusTandai selesai
Berikut RPS dari Pembelajaran ini, silahkan diunduh:
-
Siswa harusTandai selesai
1) Sikap : cara menyampaikan pendapat dalam diskusi, dan tanggungjawab dalam menyelesaikan tugas
2) Pengetahuan : penguasaan materi yang ditunjukkan dalam diskusi, presentasi, ujian tengah semester dan ujian akhir semester
3) Keterampilan : Diskusi, Gagasan dan Ide, Presentasi, Analisis
Butir Penilaian (bobot)
UAS : 30 %, UTS: 30%, Kehadiran: 10%, Keaktifan dan Partisipasi: 10%, Tugas: 20%
-
Siswa harusTandai selesai
-
Siswa harusTandai selesai
1. Ross, S. 2019. Introduction to Probability Models. .12th Edition. Elsevier. Amsterdam
2. Walpole, Myer and Ye.2012. Probability & Statistics for Engineers & Scientists. Ninth Edition. Prentice Hall.
3. Anto Dayan, Pengantar Statistika, LP3ES
4. Levine, 2012. Statitistics for Manager, Prentice Hall
5. Nathan Yau. 2011. Visualize This. New Jersey: Wiley.
-
-
-
Siswa harusTandai selesai
Pengertian Statistika Statistika adalah metode ilmiah untuk mengelola data berdasarkan angka dan menginterpretasikannya. Dalam sudut pandang penelitian, terdapat beberapa peranan statistika, yaitu: Untuk memahami keragaman nilai dari sejumlah sasaran pengamatan. Memudahkan penelitian dengan tabel, grafik, bagan, dan sebagainya. Gambaran umum terkait angka. Memudahkan dalam melakukan penarikan kesimpulan. Berdasarkan fase dan tujuan analisis, statistika dapat dibagi menjadi dua jenis, yaitu statistika deskriptif dan statistika inferensial.
Statistika deskriptif berfungsi untuk mendeskripsikan atau memberi gambaran seperti adanya terhadap objek yang diteliti menggunakan data sampel, populasi, tanpa melakukan analisis dan membuat suatu generalisasi. Sedangkan statistika inferensial merupakan satu di antara bentuk statistika yang prosesnya memungkinkan diambilnya kesimpulan secara umum terhadap data yang diolah. -
-
Siswa harusTandai selesai
Silahkan anda absen disini :
-
-
-
Siswa harusTandai selesai
Pengertian Probabilitas
Peluang atau probabilitas (probability) merupakan sebuah nilai yang digunakan untuk menghitung besar peluang terjadinya suatu kejadian.
Probabilitas memiliki cakupan yang luas, baik dalam ilmu matematika maupun statistika.
Dalam ilmu statistika, probabilitas dapat digunakan untuk uji coba produk perusahaan, statistika penduduk, dan lain-lain.
Seperti yang sudah dijelaskan sebelumnya, probabilitas memiliki nilai antara 0 (nol) hingga 1 (satu).
Jika lebih atau kurang, maka dapat dikatakan bahwa nilai probabilitas salah.
Simbol probabilitas adalah P(A), P merupakan peluang kejadian, sementara A adalah kejadian.
Jadi, dapat dikatakan bahwa nilai probabilitas adalah 0 < P(A) < 1.
ΓÇ£Probabilitas merupakan nilai yang digunakan untuk menghitung besar peluang kejadian dan memiliki nilai dari 0 (nol) hingga 1 (satu).ΓÇ¥
-
Siswa harusTandai selesai
Silahkan anda unduh materi sbb:
https://drive.google.com/file/d/1I-AJy56J3HZunW47y0w3DlNuPJt1DKRJ/view?usp=sharing
-
Siswa harusTandai selesai
Visualisasi data atau data visualization adalah representasi grafis dari data untuk membantu orang memahami konteks dan signifikansi.
Seperti yang anda tahu, umumnya data mentah terdiri dari angka dan huruf saja. Sehingga, agar data mudah dipahami oleh orang lain perlu diolah terlebih dahulu. Nah, di sinilah peran dari data visualisasi. Tujuan visualisasi data sendiri yakni untuk menyampaikan informasi secara ringkas dan jelas sehingga mudah dipahami oleh pembaca.
Nggak cuma itu aja, ada lagi manfaat visualisasi data lainnya yakni untuk membantu pembaca memprediksi tren yang ada serta membuat keputusan menjadi lebih cepat. Untuk memvisualisasikan data, elo bisa menggunakan beberapa tools seperti Google Data Studio, Tableau, dan lain sebagainya.
-
Siswa harusTandai selesai
Saturday, Oct 22 ΓÇó 8:20 ΓÇô 10.00 AM
Google Meet joining info
Video call link: https://meet.google.com/txu-vucg-gfk
-
-
-
Siswa harusTandai selesai
Kaidah Pencacahan
sebuah aturan untuk mengetahui banyaknya objek atau kejadian tertentu yang muncul. Disebut sebagai pencacahan yakni karena hasilnya berwujud bilangan cacah.
Dalam kaidah pencacahan, terdapat tiga metode yang bisa kamu gunakan, yaitu metode aturan pengisian tempat (Filling Slots), metode permutasian dan juga metode kombinasi.
1. Aturan Pengisian Tempat (Filling Slots)
Aturan pengisian tempat bisa dipahami secara mudah dengan menjabarkannya dalam pasangan terurut. Apabila suatu kejadian pertama bisa terjadi dengan lambang
cara yang tidak sama, kejadian kedua pun bisa terjadi dengan cara berbeda, dan seterusnya, maka kejadian tersebut secara berturut-turut menjadi:
cara yang tidak sama.
Sebagai contoh:
Seorang ibu memiliki 5 buah baju dan 3 buah kerudung yang masing-masing memiliki warna berbeda. Berapa pasangan warna baju dan kerudung yang bisa dibuat? Jika himpunan baju adalah k = (
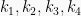 )= 5
buah, dan himpunan kerudung adalah d = (
)= 5
buah, dan himpunan kerudung adalah d = ( ) = 3 buah.
) = 3 buah.Maka bisa ditentukan bahwa:
 = 5 x 3 = 15 cara
= 5 x 3 = 15 cara2. Permutasi
Permutasi adalah susunan berurutan dari sebagian atau semua elemen dalam sebuah himpunan. Untuk menentukan permutasi, kamu harus terlebih dahulu mengetahui faktorial. Dimana hasil kali bilangan buat 1 sampai dengan n adalah n! (dibaca: n faktorial) atau:
Contoh:
5! = 5 x 4 x 3 x 1 = 120. Untuk menyelesaikan soal permutasi ini, kamu bisa menggunakan 4 metode, yakni:
- Permutasi dari elemen berbeda
Permutasi elemen dari setiap elemen yang berbeda ialah susunan elemen itu pada suatu urutan yang diperhatikan. Jadi, jika (r > n), maka permutasiannya adalah:
sehingga, jika n = r, maka permutasiannya adalah:
Sebagai contoh:
Susunlah 3 elemen dari 3 huruf, a, b, c adalah a,b,c a,c,b b,a,c c,a,b c,b,a dengan
. Sementara susunan 2 elemen dari 3 huruf ialah menggunakan
.
2. Permutasi dengan beberapa elemen sama
Masing-masing unsur yang dipakai tidak boleh lebih dari satu kali. Banyaknya permutasi elemen n yang dapat dimuat elemen adalah
dengan
ialah:
Sebagai contoh:
Ada tiga bola volly dan 2 bola basket. Maka jumlah cara menyusunnya adalah sebagai berikut:
3. Permutasi Siklis
Rumus dari permutasi siklis umumnya diterapkan untuk menghitung banyak cara yang bisa dibuat dalam susunan melingkar. Berikut ini rumus permutasi siklis:
P(siklis) = n ΓÇô 1)!
Sebagai contoh:
Banyaknya cara 5 orang yang duduk melingkar dalam sebuah meja adalah
P = (5 ΓÇô 1)! = 4 x 3 x 2 x 1 = 24
4. Permutasi berulang
Permutasi berulang ialah permutasi dimana penyusunan urutannya diperhatikan dan suatu objek bisa dilihat secara berulang (lebih dari satu kali). Banyaknya permutasi berulang ialah:
Untuk rumus permutasi berulang sendiri adalah sebagai berikut:
3. Kombinasi
Kombinasi merupakan pengelompokan dari sebagian atau seluruh elemen pada suatu himpunan tanpa memperhatikan urutan susunan pemilihannya terlebih dahulu.
Rumus dari kombinasi ialah sebagai berikut:
Sebagai contoh:
Kombinasi elemen dari 3 huruf a,b,c adalah ab, ac, bc. Sementara ba, ca, cb bukan termasuk dalam hitungan, sebab pada kombinasi ab=ba, ac=ca, bc=cb. Banyak kombinasinya adalah:
-
-
-
-
Siswa harusTandai selesai
Sebelum membahas apa itu pengertian distribusi probabilitas menurut ahli, lebih dahulu Anda harus mengetahui apa itu pengertian distribusi probabilitas secara umum. Distribusi probabilitas merupakan bagian dari fungsi matematika. Distribusi probabilitas tersebut muncul dengan berbagai kemungkinan hasil untuk suatu eksperimen.
Dengan demikian, distribusi probabilitas dapat diartikan sebagai fungsi statistik yang bertujuan untuk mendeskripsikan semua kemungkinan nilai dan juga kemungkinan yang dapat diambil dari berbagai variabel acak pada rentang tertentu. Dalam hal ini, kisaran distribusi frekuensi tersebut dibatasi oleh nilai minimum dan nilai maksimum di mana terjadi nilai kemungkinan yang akan diplot tergantung pada jumlah faktornya.
Beberapa faktor yang memengaruhi distribusi probabilitas tersebut di antaranya rata-rata distribusi atau rata-rata, deviasi standar, kemiringan, dan kurtosis. Sehingga dapat disimpulkan bahwa pengertian distribusi probabilitas secara umum adalah suatu distribusi yang menggambarkan tentang peluang dari sekumpulan variasi sebagai pengganti frekuensi.
Distribusi probabilitas ini membutuhkan kunci penerapan atau aplikasi probabilitas dalam statistik, yakni memperkirakan terjadinya peluang atau probabilitas yang kemudian akan dikaitkan dengan terjadinya suatu peristiwa dalam beberapa keadaan atau peristiwa.
Sehingga dalam hal ini, ketika Anda mengetahui bahwa keseluruhan probabilitas dari suatu kemungkinan atau outcome terjadi, maka seluruh probabilitas peristiwa atau kejadian tersebut akan membentuk suatu distribusi probabilitas.
Distribusi probabilitas ini merupakan model matematik yang mana akan menghubungkan seluruh nilai variabel acak atau random dengan peluang terjadinya nilai tersebut di dalam ruang sampel, sehingga distribusi probabilitas tersebut dianggap sebagai frekuensi relatif dengan jangka panjang.
Misalkan jika digambarkan sebagai berikut ini. Sebuah variabel yakni variabel random X adalah fungsi dari S ruang sampel ke bilangan real R, yang kemudian ditulis X : S -> R. Untuk menjawab persoalan tersebut, ada pilihan dua kali terhadap B atau benar dan juga S atau salah.
Sehingga di dalam ruang sampelnya, tertulis S = {SS, SB, BS, BB}. Sehingga jika X merupakan variabel random banyaknya jawaban benar. Maka X + {0, 1, 1}.
Distribusi Peluang/Probabilitas Diskrit
Distribusi peluang diskrit adalah suatu ruang sampel yang mengandung jumlah titik sampel yang terhingga atau suatu barisan unsur yang tidak pernah berakhir tetapi yang sama banyaknya dengan bilangan cacah
Fungsi Distribusi Probabilitas
Pada dasarnya, fungsi distribusi probabilitas adalah fungsi yang memberikan nilai probabilitas untuk setiap peristiwa. Dalam hal ini, distribusi probabilitas memberikan hubungan dengan probabilitas untuk nilai yang dapat diambil dari variabel acak, yang kemudian berfungsi untuk menentukan variabel acak diskrit.
Selanjutnya, fungsi dari distribusi probabilitas tersebut digunakan untuk mewakili distribusi probabilitas di ruang sampel. Selain itu, distribusi probabilitas juga memiliki konsep fundamental di dalam statistika yang mana memiliki beberapa fungsi praktis seperti di bawah ini.
1. Distribusi probabilitas berfungsi untuk menghitung interval kepercayaan pada suatu parameter dan untuk menghitung daerah kritis pada suatu uji hipotesis.
2. Distribusi probabilitas memiliki fungsi untuk data univariat, yang mana distribusi probabilitas ini seringkali berguna untuk menentukan model distribusi yang wajar dan untuk data tersebut.
3. Distribusi probabilitas juga dapat digunakan sebagai interval statistik dan uji hipotesis yang seringkali didasarkan pada asumsi distribusi tertentu. Sehingga, sebelum menghitung interval atau melakukan pengujian berdasarkan suatu asumsi distribusi, Anda harus melakukan verifikasi bahwa asumsi tersebut dibenarkan untuk kumpulan data yang diberikan.
Mengapa demikian? Hal ini karena distribusi tersebut tidak perlu menjadi distribusi data yang paling sesuai, akan tetapi bisa menjadi model yang cukup memadai sehingga teknik statistik akan menghasilkan kesimpulan yang valid.
4. Terakhir, fungsi distribusi probabilitas ini menjadi studi simulasi dengan bilangan acak yang dihasilkan dari penggunaan distribusi probabilitas tertentu yang sering digunakan.
Ciri-ciri Distribusi Probabilitas
Untuk membedakan distribusi probabilitas dengan yang lainnya, tentu distribusi probabilitas harus memiliki ciri-ciri sebagai pembeda. Oleh sebab itu, Anda harus memahami apa ciri-ciri dari distribusi probabilitas. Di bawah ini adalah ciri-ciri dari distribusi probabilitas.
1. Distribusi probabilitas memiliki ciri-ciri yakni probabilitas atau peluang dari sebuah hasil berkisar antara 0 sampai dengan 1.
2. Ciri-ciri selanjutnya yaitu distribusi probabilitas memiliki hasil-hasil, yang mana hasilnya adalah dari kejadian yang tidak terikat antara kejadian yang satu dengan kejadian yang lain.
3. Terakhir, distribusi probabilitas ini memiliki daftar hasil yang lebih lengkap. Sehingga jumlah dari probabilitas atau peluang dari berbagai kejadian atau peristiwanya adalah 1.
Karakteristik Distribusi Probabilitas
Selain memiliki ciri-ciri yang membedakan antara distribusi probabilitas dengan distribusi yang lainnya, distribusi probabilitas juga memiliki karakter yang menjadikan distribusi probabilitas ini lebih unik atau berbeda dengan yang lain. Berikut adalah karakteristik dari distribusi probabilitas.
1. Kurva Bentuk Genta atau Lonceng
Distribusi probabilitas memiliki karakteristik yaitu memiliki kurva yang berbentuk genta atau lonceng. Dari bentuk tersebut, memiliki satu puncak yang letaknya di tengah. Sehingga dari nilai rata-rata hitungnya sama dengan median dan juga modus.
2. Berbentuk Kurva Simetris
Sementara itu, karakter selanjutnya yaitu distribusi probabilitas dan kurva normal berbentuk kurva simetris dengan rata-rata hitungnya.
3. Kurva Menurun ke Dua Arah
Selain itu, distribusi probabilitas juga memiliki karakteristik yaitu memiliki kurva yang menurun di kedua arah, yaitu ke arah kanan untuk nilai positif sampai tak terhingga, dan ke kiri untuk nilai yang negatif sampai tak terhingga.
4. Mendatar
Pada distribusi probabilitas, jika luas daerah yang terletak di bawah kurva normal tetapi di atas sumbu mendatar, sama dengan memiliki nilai 1.
-
-
Siswa harusTandai selesai
Distribusi binomial adalah distribusi probabilitas diskret banyak kesuksesan dalam n percobaan ya/tidak (berhasil/gagal) yang saling tidak terikat, dimana setiap hasil percobaan benar probabilitas p. Eksperimen berhasil/gagal juga dinamakan percobaan bernoulli. Ketika n = 1, distribusi binomial adalah distribusi bernoulli. Distribusi binomial merupakan dasar dari uji binomial dalam uji signifikansi statistik.
Distribusi ini seringkali dipakai untuk memodelkan banyak kesuksesan pada banyak sampel n dari banyak populasi N. Apabila sampel tidak saling tidak terikat (yakni pengambilan sampel tanpa pengembalian), distribusi yang dihasilkan adalah distribusi hipergeometrik, bukan binomial. Semakin agung N daripada n, distribusi binomial merupakan pendekatan yang berpegang pada kebenaran dan banyak dipakai.
Contoh
Sebagai contoh, sebuah dadu dilempar sepuluh kali dan dihitung berapa banyak muncul angka empat. Distribusi banyak tanpa pola ini adalah distribusi binomial dengan n = 10 dan p = 1/6.
Contoh lain, sebuah uang logam dilambungkan tiga kali dan dihitung berapa banyak muncul sisi depan. Distribusi banyak tanpa pola ini merupakan distribusi binomial dengan n = 3 dan p = 1/2.
-
Siswa harusTandai selesai
Distribusi hipergeometrik merupakan distribusi diskrit. Setiap hasil (outcome) terdiri dari keberhasilan atau kegagalan. Pengambilan sampel (sampling) dilakukan tanpa pengembalian. Populasi (N) adalah terbatas dan diketahui.
Ciri-ciri percobaan Hipergeometrik : Sampel acak berukuran n diambil dari populasi berukuran N. Dari populasi berukuran N benda, sebanyak k benda diberi label ΓÇ£suksesΓÇ¥, dan N-k benda diberi label ΓÇ£gagalΓÇ¥.
Distribusi hipergeometrik digunakan ketika pengambilan sampel dilakukan tanpa pengembalian, informasi tentang susunan populasi harus diketahui untuk menentukan kembali probabilitas keberhasilan dalam setiap percobaan berturut-turut karena probabilitas berubah.
Beberapa contoh penerapan distribusi hipergeometri di kehidupan sehari-hari sebagai berikut :- Jumlah barang dagangan yang rusak dalam sampel acak dari sejumlah besar kiriman
- Jumlah orang-orang yang anda temui dalam hidup anda dengan nama Ronald
- Jumlah penny yang terambil dari dalam kendi
- Ditemukan dalam berbagai bidang dan paling serin diunakan dalam penarikan sampel penerimaan barang, penujian elektronik, jaminan mutu, dsb.
- Dalam banyak bidang ini, pengujian dilakukan terhadap barang yang di uji yang pada akhirnya barang uji tersebut menjadi rusak, sehingg tidak dapat dikembalikan. Jadi, pengembalian sampel harus dikerjakan tanpa pengembalian
-
Siswa harusTandai selesai
Silahkan anda simak disini
-
-
-
Siswa harusTandai selesai
Topic: Perkuliahan Statistika MTI Dr. Faurani
Time: Nov 5, 2022 08:15 AM Jakarta
Join Zoom Meeting
https://csueb.zoom.us/j/8148554787?pwd=LI7sU3kowSlTe64eKnFCrXNxMqpSb2.1
Meeting ID: 814 855 4787
Passcode: HMM22
-
-
-
Siswa harusTandai selesai
Distribusi normal atau distribusi Gauss merupakan salah satu jenis fungsi peluang peubah acak kontinu. Kenapa dinamakan distribusi Gauss? Jadi, nama tersebut berasal dari seorang matematikawan asal Jerman bernama Carl Friedrich Gauss.
Gauss telah mengembangkan fungsi Gauss yang sering digunakan di dalam ilmu statistika untuk mendeskripsikan distribusi normal. Grafik fungsi Gauss merupakan kurva yang memiliki bentuk lonceng.
Distribusi normal merupakan salah satu jenis pembahasan dalam statistika yang kaitannya terhadap distribusi peluang atau juga disebut distribusi probabilitas. Melalui tabel distribusi normal, kerap digunakan sebagai bahan perhitungan berbagai fenomena dalam kehidupan sehari-hari. Seperti perhitungan tinggi badan, tekanan darah, perhitungan kesalahan hingga penjabaran nilai IQ.
Istilah distribusi normal juga disebut juga dengan distribusi Gauss, persamaan yang ada dalam distribusi normal dan salah satunya adalah fungsi densitas. Dalam suatu teori distribusi peluang atau probabilitas, distribusi normal menempati posisi paling penting dan terdapat dalam berbagai analisa statistik terhadap bahan yang didapat.
Untuk memahami lebih jelas silahkan anda downoad materi sebagai berikut:
-
Siswa harusTandai selesai
Pengertian fungsi eksponensial Dilansir dari Encyclopedia Britannica, fungsi eksponensial adalah fungsi nonaljabar atau transcendental yang tidak dapat direpresentasikan sebagai produk, jumlah, dan perbedaan variabel yang dipangkatkan ke bilangan bulat non-negatif. Fungsi eksponensial merupakan fungsi berpangkat, yang pangkatnya memiliki variabel. Jika biasanya fungsi memiliki basis berupa variabel dan pangkat atau eksponen berupa konstanta, maka fungsi eksponensial adalah sebaliknya. Fungsi ekponensial memiliki basis berupa konstanta dan pangkat atau eksponen berupa variabel atau mengandung variabel (kombinasi antara konstanta dan variabel).
Fungsi eksponensial memiliki grafik yang unik. Grafik eksponensial bukan berbentuk garis lurus, melainkan garis lengkung yang menurun atau menanjak. Bentuk umum fungsi eksponensial Fungsi eksponensial memiliki bentuk umum berupa:
f(x) = a^x
Dengan, a: konstanta x: variabel
Nilai harus lebih besar dari nol dan tidak boleh sama dengan satu. Dilasir dari Mathematics LibreTexts, hal tersebut dikarenakan basis fungsi eksponensial harus positif agar hasil yang didapatkan juga berupa bilangan real.Jika basis (a) fungsi eksponensial adalah bilangan di bawah nol (bilangan negatif), maka hasil yang didapatkannya juga bukanlah bilangan real. Nilai basis (a) fungsi ekponensial juga tidak boleh sama dengan satu (1). Nilai a yang sama dengan satu akan membuat hasil fungsinya konstan dan membentuk garis lurus yang berarti bukan persamaan eksponensial. Bentuk fungsi eksponensial yang paling sering digunakan adalah f(x) = e^x. Dilansir dari Cuemath, e adalah bilangan euler yaitu 2,718…
Penyelesaian fungsi eksponensial Seperti fungsi pada umumnya, bilangan eksponensial memiliki penyelesaian yang bergantung pada bentuk fungsinya. Berikut adalah rumus penyelesaian fungsi eksponensial: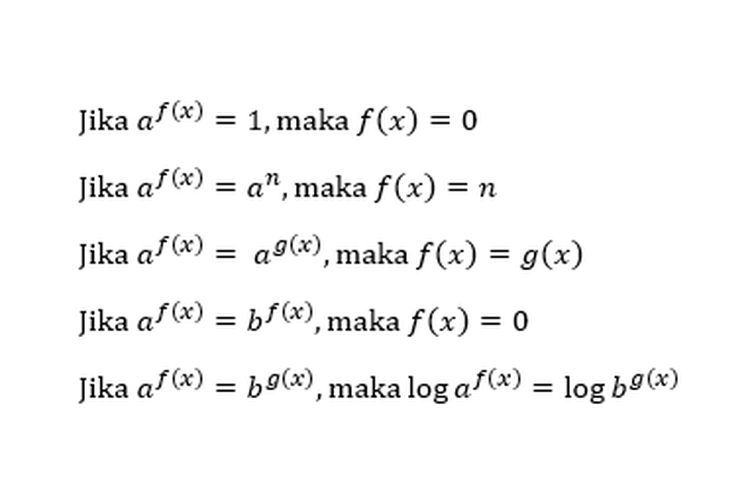
Selain rumus fungsi eksponensial di atas, beberapa fungsi eksponensial memiliki kemungkinan penyelesaian yang lebih dari satu sebagai berikut* Jika f(x)^g(x) = 1, maka kemungkinan penyelesaianya ada tiga yaitu:
f(x) = 1
f(x) = -1 (g(x) harus genap)
g(x) =0 (f(x) tidak boleh sama dengan nol)
* Jika f(x)^h(x) = g(x)^h(x), maka kemungkinan penyelesaiannya ada tiga yaitu:
f(x) = g(x)
f(x) = - g(x) (h(x) harus genap)
h(x) = 0 (f(x) dan g(x) tidak boleh sama dengan nol)
* Jika f(x)^g(x) = f(x)^h(x), maka kemungkinan penyelesaiannya ada empat yaitu:
g(x) = h(x)
f(x) = 1
f(x) = -1 (g(x) dan h(x) sama-sama genap atau sama-sama ganjil)
f(x) = 0 (g(x) dan h(x) lebih besar dari nol)
-
Siswa harusTandai selesai
Distribusi uniform diskrit adalah distribusi yang peubah acaknya memperoleh semua nilainya dengan peluang yang sama.
Bentuk fungsi kepadatan peluang kontinu yang paling sederhana adalah fungsi kepadatan peluang yang bernilai konstan pada seluruh daerah rentangnya. Peubah acak yang memounyai fungsi kepadatan peluang demikian dikatakan berdistribusi uniform.

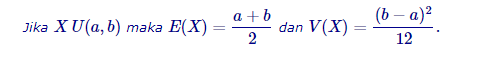
-
-
-
Siswa harusTandai selesai
Dalam bagian ini, Anda akan belajar:
- Untuk menghitung probabilitas dari distribusi normal.
- Untuk menggunakan plot probabilitas normal untuk menentukan apakah sekumpulan data berdistribusi mendekati normal.
- Untuk menghitung probabilitas dari distribusi seragam.
- Untuk menghitung probabilitas dari distribusi eksponensial
Untuk lebih jelas lagi silahkan anda download materi PPt dari buku Statistics for Manager (by Levine et al. 2010) sebagai berikut:
-
Siswa harusTandai selesai
Distribusi sampel adalah distribusi dari rata-rata atau proporsi sampel yang diambil secara berulang-ulang (n kali) dari populasi. menunjukkan distribusi dari nilai ΓÇô nilai yang berbeda statistik sampel atau penduga dari banyak sampel yang berukuran sama.
Distribusi sampling adalah distribusi peluang untuk nilai statistik yang diperoleh dari sampel acak untuk menggambarkan populasi.Distribusi sampling merupakan faktor penting dalam analisis statistik, karena memberikan penyederhanaan utama dalam perjalanan ke inferensi statistik (Pengambilan keptusan).- Distribusi rata-rata
- Distribusi selisih dan jumlah rata-rata
- Distribusi proporsi
- Distribusi selisih proporsi.
Proses sampling merupakan proses mengubah sinyal analog yang berbentuk sinyal waktu kontinu menjadi sinyal waktu diskrit. Untuk mendapatkan sinyal waktu diskrit yang mampu mewakili sifat sinyal aslinya, proses sampling harus memenuhi syarat.
Untuk mengambil sampel, teknik sampling terbagi menjadi dua kategori, yaitu probability sampling dan non-probability sampling.
Probability sampling dan non probability sampling- Probability sampling adalah teknik sampling yang di mana setiap individu dalam populasi memiliki peluang untuk terpilih. ...
- Sedangkan non probability sampling merupakan teknik sampling di mana tidak setiap individu dalam populasi memiliki peluang untuk terpilih.
Manfaat sampling adalah:
Menghemat waktu untuk penelitian. Dapat menghasilkan data yang lebih akurat. Memperluas ruang lingkup penelitian.Cara Melakukan Pengambilan SampelPerbedaan populasi dan sampel, yaitu populasi fokusnya kepada semua objek yang diteliti sedangkan sampel hanya sebagian kecil dari populasi yang diambil untuk diteliti dan dianggap bisa mewakili populasi.- Mendefinisikan populasi yang akan diamati.
- Menentukan kerangka sampel dan kumpulan semua peristiwa yang dapat terjadi.
- Menentukan teknik atau metode sampling yang tepat.
- Melakukan pengambilan sampel (pengumpulan data)
- Melakukan pemeriksaan ulang pada proses sampling.
Sampel merupakan faktor penting dalam penelitian karena sangat berpengaruh terhadap kualitas penelitian yang dihasilkan. Kesalahan-kesalahan dalam penentuan sampel harus diminimalkan untuk menghasilkan sampel yang tingkat akurasi, validitas dan reliabilitasnya tinggi.
Kesalahan sampling adalah kekeliruan yang disebabkan oleh kenyataan adanya pemeriksaan yang tidak lengkap terhadap populasi. Kekelirun sampling adalah perbedaan antara hasil sampel dan hasil yang akan dicapai jika prosedur yang sama digunakan dalam sensus (Sudjana, 1996 : 176).
Terdapat dua syarat yang harus dipenuhi dalam prosedur pengambilan sampel, yaitu representatif (dapat mewakili karakteristik populasi) dan besamya memadai (Atherton. dan Clemmack, 1982 dalam Busnawir).
Yaitu terkait dengan hal- hal yang harus diperhatikan oleh peneliti dalam menentukan besar sampel, di antaranya adalah :- Tingkat homogenitas anggota populasi.
- Presisi yang diharapkan peneliti.
- Rancangan analisis data penelitian.
- Ketersediaan dana, waktu dan tenaga penelitian
Penentuan Sample:1. Rumus Slovin digunakan untuk menentukan ukuran sampel dari populasi yang telah diketahui jumlahnya yaitu sebanyak 779 siswa. Untuk tingkat presisi yang ditetapkan dalam penentuan sampel adalah 10%. Alasan peneliti menggunakan tingkat presisi 10% karena jumlah populasi kurang dari 1000.
2. Jumlah sampel diambil adalah sebesar 30 responden, hal ini sesuai pendapat Singarimbun dan Effendi (1995) yang mengatakan bahwa jumlah minimal uji coba kuesioner adalah minimal 30 responden. Dengan jumlah minimal 30 orang maka distribusi nilai akan lebih mendekati kurve normal.
-
-
-
SOAL UTS Penugasan
BAGIAN I (Kerjakan dalam file excel)
1. Berikut ini adalah data variabel X dan variabel Y yang mempunyai satuan pengukuran kilogram. Hasil pengukuran-nya adalah :
Variabel X : 20 21 18 15 25 18 22
Variabel Y : 25 30 28 22 19 21 16
a. Apa skala pengukuran variabel X ?
b. Hitunglah mean, median, modus, Q1 , Q3, dan standar deviasi dari variabel X !
c. Buatlah gambar distribusi nya kemudian tentukan kecondongan (skewness), dan keruncingan (kurtosis) kemudian analisiskan hasil dari perhitungan (b) dan gambar (c)
2. Diketahui: Distribusi nilai ujian statistika adalah sebagai berikut :
37
44
43
26
51
37
27
31
51
30
29
24
26
26
27
38
34
34
48
38
37
44
23
39
26
38
23
41
55
28
39
30
32
24
33
29
32
30
38
38
36
25
28
31
32
38
29
33
30
25
a. Buatlah tabel distribusi frekuensi dengan banyaknya kelas 7 dan panjang kelasnya 5
- Hitunglah mean, median, modus, Q1, P25, dan standar deviasi-nya !
- Tentukan batas terendah dari 25% nilai yang tertinggi !
- Jelaskan kemiringan kurva dari nilai ujian statistika !
- Buatlah grafik histogram distribusi frekuensi nya, kemudian analisiskan!
BAGIAN II (Kerjakan dalam bentuk word version)
1. Dari keseluruhan barang yang diproduksi, 10% -nya rusak. Diambil sampel sebanyak 10 barang, berapa probabilitas barang yang terambil tersebut :
a. terambil 1 yang rusak ?
b. tidak ada yang rusak ?c. paling banyak 2 yang rusak ?
2. Di kelas A sebanyak 30 orang, terdapat 6 orang dengan IPK kurang dari 2. Apabila diambil 5 orang , berapa probabilitas :
a. terdapat 1 orang mahasiswa dengan IPK kurang dari 2
b. paling sedikit 3 orang mahasiswa denga IPK kurang dari 2.
TERIMA KASIH DAN SELAMAT MENGERJAKAN
1. Untuk Jawaban dikumpulkan via LMS dan Portal Student pada pertemuan UTS mlai hari Sabtu tanggal 25 November pukul 08.00 WIB sampai dengan 02 Desember 2022 pukul 13.00 WIB
2. Untuk jawabn Bagian 1 kerjakan dalam bentuk file excel dan untuk bagian ke-2 kerjakan dalam bentuk word/pdf. Jawaban dikerjakan dan dikumpulkan secara individu masukan dalam 1 folder yang berisi 2 file (excel untuk soal bagian 1 dan word version untuk soal bagian 2) beri nama folder dengan format : Nama_NPM_Kelas
3. Jika Ada masalah dengan LMS/portal student Anda silahkan hub WA grup Kelas /081934190942 (Bu. Faurani)
-
-
-
Siswa harusTandai selesai
Apa yang dimaksud dengan Populasi dan Sampel? Secara simpelnya, Populasi ada keseluruhan data yang diobservasi, sedangkan sampel adalah sebagian dari populasi tersebut. Mari kita bahas dalam pembelajaran kali ini secara detail dan gamblang tentang Populasi dan Sampel tersebut serta perbedaan diantara keduanya. Perbedaan Populasi dan Sampel harus dipahami secara jelas agar tidak salah saat para peneliti melakukan penentuan dan pengambilan data.
Pengertian Teknik sampling adalah teknik pengambilan sampel dari populasi. Sampel yang merupakan sebagian dari populasi tersebut, kemudian diteliti dan hasil penelitian (kesimpulan) kemudian dikenakan pada populasi (generalisasi).
Secara umum, ada dua jenis teknik pengambilan sampel yaitu, sampel acak atau random sampling yang dikenal juga sebagai probability sampling, dan sampel tidak acak atau nonrandom samping yang dikenal juga sebagai non probability sampling. Untuk lebih jelasnya, kita akan ulas satu per satu pada artikel ini.
-
Teknik Sampel
-
-
-
-
Siswa harusTandai selesai
Confidence Interval dalam statistik, mengacu pada probabilitas bahwa parameter populasi akan berada di antara sekumpulan nilai untuk proporsi waktu tertentu.
Memahami Apa itu Confidence Interval
Confidence Interval mengukur tingkat ketidakpastian atau kepastian dalam metode pengambilan sampel. Mereka dapat mengambil sejumlah batas probabilitas, dengan yang paling umum adalah tingkat kepercayaan 95% atau 99%. Confidence Interval dilakukan dengan menggunakan metode statistik, seperti uji-t.
Ahli statistik menggunakan Confidence Interval untuk mengukur ketidakpastian dalam variabel sampel. Misalnya, seorang peneliti memilih sampel yang berbeda secara acak dari populasi yang sama dan menghitung Confidence Interval untuk setiap sampel untuk melihat bagaimana hal itu dapat mewakili nilai sebenarnya dari variabel populasi. Kumpulan data yang dihasilkan semuanya berbeda; beberapa interval menyertakan parameter populasi sebenarnya dan yang lainnya tidak.
Confidence Interval adalah rentang nilai, dibatasi di atas dan di bawah rata-rata statistik, yang kemungkinan akan berisi parameter populasi yang tidak diketahui. Tingkat kepercayaan mengacu pada persentase probabilitas, atau kepastian, bahwa Confidence Interval akan berisi parameter populasi sebenarnya ketika Anda menggambar sampel acak berkali-kali. Atau, dalam bahasa sehari-hari, ΓÇ£kami 99% yakin (tingkat kepercayaan) bahwa sebagian besar sampel ini (Confidence Interval) berisi parameter populasi yang sebenarnya.ΓÇ¥
Kesalahpahaman terbesar mengenai Confidence Interval adalah bahwa mereka mewakili persentase data dari sampel tertentu yang berada di antara batas atas dan bawah. Misalnya, seseorang mungkin secara keliru menafsirkan Confidence Interval 99% yang disebutkan di atas dari 70 hingga 78 inci sebagai menunjukkan bahwa 99% data dalam sampel acak berada di antara angka-angka ini. Ini tidak benar, meskipun ada metode analisis statistik yang terpisah untuk membuat penentuan seperti itu. Melakukannya melibatkan mengidentifikasi mean dan standar deviasi sampel dan memplot angka-angka ini pada kurva lonceng.
-
-
-
-
-
Siswa harusTandai selesai
Silahkan anda Pelajari Contoh soal Penentuan Sampel Size dan Confidence Interval Estimation sbb:
-
-
-
-
-
Siswa harusTandai selesai
Topic: Statistik dan Data Analisis kelas MTI Dr. Faurani
Time: Dec 03, 2022 08:30 AM Jakarta
Join Zoom Meeting
https://csueb.zoom.us/j/8148554787?pwd=LI7sU3kowSlTe64eKnFCrXNxMqpSb2.1
Meeting ID: 814 855 4787
Passcode: HMM22
-
-
-
Siswa harusTandai selesai
Dalam struktur penelitian - utamanya penelitian kuantitatif - hipotesis menjadi poin yang penting dalam penelitian. Kenapa? Karena hipotesis menjadi dasar dugaan substansial dari peneliti mengenai topik permasalahan penelitian untuk nantinya dibuktikan dalam proses penelitian secara metodologis, ilmiah, dan empiris.
Hipotesis adalah proposisi yang sifatnya belum terbukti secara ilmiah. Sehingga proposisi ini harus segera dibuktikan secara empiris dengan proses penelitian yang sesuai dengan metodologi yang sesuai.Jenis Hipotesis
Khususnya dalam penelitian korelasi dan komparatif, hipotesis adalah proposisi yang memiliki dua jenis yaitu hipotesis tanpa arah (dua arah) dan hipotesis searah. Bagaimana penjelasannya?
A. Hipotesis Tanpa Arah (Dua Arah)
Jenis pertama yaitu hipotesis tanpa arah yang sering disebut juga sebagai hipotesis dua arah. Hipotesis tanpa arah rumusan dari kalimat atau proposisi yang berisi pernyataan hanya mengenai adanya hubungan atau tidak adanya hubungan.
Di mana hipotesis jenis ini tidak ikut menjelaskan arah hubungan antara variabel yang diteliti secara metodologis. Contohnya, hipotesis yang menyatakan "Ada hubungan yang signifikan antara Motivasi Belajar dengan Prestasi Belajar Siswa".
B. Hipotesis Searah
Selanjutnya, ada hipotesis searah yang merupakan pernyataan yang menunjukkan arah hubungan dan perbedaan antara dua atau lebih variabel yang diteliti secara metodologis. Arah hubungan dan perbedaan ini menunjukkan aspek positif atau negatif yang saling berimplikasi.
Adapun contoh dari hipotesis searah dalam konteks penelitian, seperti hipotesis yang menyatakan "Semakin tinggi motivasi belajar siswa maka diikuti semakin tinggi prestasi siswa" dan "Semakin tinggi konsep diri maka diikuti semakin rendah agresivitas siswa". -
Siswa harusTandai selesai
-
Siswa harusTandai selesai
Topic: Perkuliahan Statsitik dan Data Analisis MTI Dr. Faurani
Time: Dec 167 2022 08:15 AM Jakarta
Join Zoom Meeting
https://csueb.zoom.us/j/8148554787?pwd=LI7sU3kowSlTe64eKnFCrXNxMqpSb2.1
Meeting ID: 814 855 4787
Passcode: HMM22
-
-
-
Siswa harusTandai selesai
ANALISIS DATA
1. Univariat, Bivariat, dan Multivariat
Univariate Analysis, adalah analisis yang dilakukan untuk satu variabel atau per variabel.
Catatan: Dalam pengertian tertentu, analisis deskriptif menjadi sama dengan analisis univariat.
Bivariate Analysis, adalah analisis yang dilakukan untuk menganalisis hubungan dua variabel.
Multivariate Analysis, adalah analisis yang dilakukan untuk menganalisis hubungan lebih dari dua variabel.
Catatan: Karena pada saat sekarang kecenderungan penelitian melibatkan banyak variabel, maka terjadi kecenderungan analisis multivariat pula. Agar penamaan analisis multivariat tidak menjadi suatu analisis yang ΓÇ¥biasaΓÇ¥, maka sekarang digunakan pengertian lain dalam analisis hubungan asimetrik, yaitu;
Univariate Analysis, adalah analisis yang dilakukan pada dua atau lebih variabel yang hanya memiliki 1 variabel terikat.
Dengan pengertian ini, analisis univariat menjadi tak sama lagi dengan analisis deskriptif.
Multivariate Analysis, adalah analisis yang dilakukan pada tiga atau lebih variabel yang memiliki dua atau lebih variabel terikat.
Program SPSS menggunakan konsep seperti ini.
2. Parametrik dan Nonparametrik
Parametric Analysis, analisis yang dilakukan untuk menguji parameter/berdasarkan asumsi-asumsi tertentu dan biasanya salah satu asumsinya adalah distribusi normal.
Catatan: keluarga distribusi normal antara lain adalah;
a. Distribusi Gauss
b. Distribusi Fisher
c. Distrbusi Student.
Nonparametric Analysis, analisis yang dilakukan tidak untuk menguji parameter/tidak berdasarkan asumsi-asumsi tertentu.
Catatan: salah satu keluarga distrbusi yang termasuk dalam kategori statistika bebas distribusi (free distribution statistics) dan untuk memahami masing-masing metode analisis data dapat dilihat pada slide PPT materi dan video sbb:
-
-
-
Siswa harusTandai selesai
Topic: Perkuliahan statistik Dr. Faurani
Time: Jan 07, 2023 08:30 AM Jakarta
Join Zoom Meeting
https://csueb.zoom.us/j/8148554787?pwd=LI7sU3kowSlTe64eKnFCrXNxMqpSb2.1
Meeting ID: 814 855 4787
Passcode: HMM22
-
-
-
Siswa harusTandai selesai
ANALISIS FAKTOR
Analisis faktor adalah metode untuk mengetahui interdependensi (saling mempengaruhi) antar variabel independen. Dalam sebuah data yang besar dengan banyak variabel independen, misalnya 15 variabel independen (15 sebagai angka contoh, bisa kurang atau bisa lebih dari itu), bisa jadi sebenarnya 15 variabel tersebut hanya mewakili 1 atau 2 faktor dasar yang sama. Analisis faktor digunakan untuk mereduksi variabel sehingga persamaan menjadi lebih efektif dan simpel.
Contoh: Dalam penelitian pengaruh iklan online terhadap peningkatan konsumsi, variabel 1 iklan di platform video (youtube), variabel 2 iklan di media sosial (tiktok, ig), variabel 3 iklan di webpage, ketiganya bisa jadi sebagai observed variable mewakili 1 faktor lokasi iklan terkait traffic tinggi; sedangkan variabel lain semisal frekuensi dan durasi masih menjadi unobserved variable. Observed variable adalah variabel yang disertakan dalam penelitian, dan unobserved variable adalah variabel yang tidak diteliti.
Berikut penjelasan dalam PPT dan modul mengerjakan dengan SPSS beserta Data dan output latihan
https://drive.google.com/drive/folders/1XlUSjtRBCE-ZwFglWs3xWXxKGMqHFJRJ?usp=share_link
-
Siswa harusTandai selesai
ANALISIS KLASTER
Analisis klaster adalah metode statistik dalam penelitian yang memungkinkan peneliti untuk mengelompokkan atau mengelompokkan sekumpulan objek ke dalam kluster-kluster kecil namun berbeda yang berbeda karakteristiknya dari kluster-kluster lain yang berbeda. Tema yang mendasari dalam analisis data eksplorasi membantu merek, organisasi, dan peneliti memperoleh wawasan dari data visual untuk melihat tren dan memvalidasi hipotesis dan asumsi eksplisit.

Metode analisis dalam penelitian ini umumnya didasarkan pada analisis data statistik yang digunakan di berbagai bidang, termasuk pengenalan pola, pembelajaran mesin, manajemen wawasan dalam riset pasar, scrubbing data, bioinformatika, dan banyak lagi.
Tujuan dari analisis klaster adalah untuk menemukan kelompok objek dengan perubahan perilaku yang berbeda tetapi di mana karakteristik yang mendasari dan hal-hal tersebut berada dalam kelompok kontrol yang sama. Contoh yang sangat baik dari metode penelitian ini adalah bank yang menggunakan data kualitatif dan kuantitatif untuk memplot tren dalam pemrosesan klaim di antara klien. Menggunakan analisis klaster membantu mereka menyimpulkan klaim penipuan dan lebih memahami perilaku konsumen.
Metode Analisis Cluster
Analisis klaster membantu peneliti dan ahli statistik untuk memahami data secara lebih mendalam dan membuat keputusan yang lebih baik. Sementara data dapat menjadi bagian dari penelitian kualitatif atau penelitian kuantitatif, analisis data masih dilakukan dalam platform penelitian di mana data diplot pada grafik. Namun, seperti disebutkan di atas, berbagai metode analisis klaster digunakan untuk memenuhi kebutuhan penelitian.
Namun, penting untuk dicatat bahwa metode pengelompokan perlu dipilih secara eksperimental kecuali ada penalaran matematis yang sesuai dengan cara tertentu. Mari kita lihat metode analisis cluster yang paling umum digunakan.
Analisis klaster dibagi menjadi dua metode yaitu metode hirarki dan metode non- hirarki. Metode hirarki dibagi menjadi dua, yaitu metode aglomeratif dan metode difisif. Pada metode agglomeratif, langkah pertama masing-masing obyek pengamatan dijadikan sebagai kelompok yang memiliki satu anggota setiap kelompok.
-
Siswa harusTandai selesai
PATH ANALISIS (ANALISIS JALUR)
Siapa yang disini sering mendengar tentang path analysis? Sahabat data disini pasti belum familiar dengan analisis yang satu ini. Kalau bisa dibilang analisis ini tergolong analisis yang baru dan mulai diterapkan sebagai alat analisis dalam bidang ilmu sosial. Sebenarnya path analysis ini merupakan pengembangan korelasi yang diurai menjadi beberapa interpretasi akibat yang ditimbulkannya.
Sewall Wright adalah seorang ahli genetika yang mengembangkan path analysis untuk membuat kajian hipotesis hubungan sebab akibat dengan menggunakan korelasi. Lebih lanjut, path analysis mempunyai kedekatan dengan regresi berganda; atau dengan kata lain, regresi berganda merupakan bentuk khusus dari path analysis. Teknik ini juga dikenal sebagai model sebab-akibat (causing modeling). Penamaan ini didasarkan pada alasan bahwa analisis jalur memungkinkan pengguna dapat menguji proposisi teoritis mengenai hubungan sebab dan akibat tanpa memanipulasi variabel-variabel. Memanipulasi variabel maksudnya ialah memberikan perlakuan (treatment) terhadap variabel-variabel tertentu dalam pengukurannya.
Asumsi dasar model ini ialah beberapa variabel sebenarnya mempunyai hubungan yang sangat dekat satu dengan lainnya. Dalam perkembangannya saat ini path analysis diperluas dan diperdalam kedalam bentuk analisis (Structural Equation Modeling) atau dikenal dengan singkatan SEM. Tidak heran jika analisis ini tergolong ke dalam penerapan dari statistik parametrik.
Path analysis memungkinkan peneliti melakukan analisis model-model yang lebih kompleks yang tidak bisa dilakukan oleh regresi linier berganda. Path analysis juga dapat digunakan untuk mengetahui hubungan langsung maupun tidak langsung, salah satunya melalui variabel intervening. Analisis jalur mempresentasikan hubungan kausal antar variabel dalam bentuk gambar agar semakin mudah dibaca. Penggambaran ini dilakukan untuk menjelaskan hubungan yang terjadi baik variabel dependen maupun independen ataupun hubungan lain terhadap variabel moderasinya. Berbeda dari analisis data regresi yang hanya mempengaruhi secara langsung. Analisis jalur mampu menganalisis data hubungan tidak langsung antar-variabel. Akibat dari keterbatasan yang dimiliki oleh analisis regresi linear berganda, maka analisis jalur atau path analysis ini dapat mengcover semua yang diperlukan untuk keperluan analisis data berdasarkan nilai yang nantinya akan dibandingkan terhadap taraf signifikansinya. Seperti apa sih lebih jelasnya mengenai analisis jalur ini? Mari kita cari tahu lebih dalam. Pada artikel DQLab kali ini, kita akan membahas lebih dalam terkait analisis jalur atau path analysis nih sahabat data. Dengan harapan bisa menjadi tambahan insight dan rekomendasi bagi kalian calon praktisi data, peneliti maupun data enthusiast. Jangan lewatkan artikel berikut ini, pastikan simak baik-baik, stay tune and keep scrolling on this article guys!
-
-
-
Siswa harusTandai selesai
Silahkan anda kerjakan soal UAS
INSTRUKSI
1. Mengisi absen saat ujian tanggal 21 Januari 2023
2. Open Book dan bisa dikerjakan dirumah (take home)
3. Dikumpulkan paling lambat hari Sabtu tanggal 28 Januari 2023 pukul 10.00 via LMS dan Portal Student dalam bentuk file word version untuk intepretasi jawaban dan output spss (dalam bentuk SAV) untuk hasil olah data
4. Buat dalam bentuk folder yang berisi file word utk jawaban intepretasi, dan file SAV untuk jawaban output olah data SPSS dengan nama folder : Nama_NPM
-