Statistika adalah
sebuah ilmu yang mempelajari bagaimana cara merencanakan, mengumpulkan, menganalisis,
lalu menginterpretasikan, dan akhirnya mempresentasikan data.Singkatnya,
statistika adalah ilmu yang bersangkutan dengan suatu data. Istilah
"Statistika" berbeda dengan "Statistik". Statistika pada
umumnya bekerja dengan memakai data numerik yang di mana adalah hasil cacahan
maupun hasil pengkuran yang dilakukan dengan menggunakan data kategorik yang
diklasifikasikan menurut sebuah kriteria tertentu.[1]
Statistika merupakan ilmu yang berkaitan dengan data.
Statistik adalah data itu sendiri, informasinya, atau hasil penerapan algoritme
statistika pada suatu data tersebut. Dari kumpulan data, statistika dapat
digunakan untuk menyimpulkan atau mendeskripsikan data; inilah yang
dinamakan statistika deskriptif. Informasi
kemudian dicatat sekaligus dikumpulkan baik itu dalam bentuk informasi numerik
maupun informasi kategorik yang disebut sebagai suatu pengamatan. Sebagian
besar konsep dasar statistika memberi asumsi mengenai teori probabilitas. Beberapa istilah
statistika antara lain sebagai berikut: populasi, sampel, unit sampel, probabilitas.
Statistika juga telah banyak diterapkan dalam berbagai
disiplin ilmu, baik itu ilmu-ilmu alam (misalnya astronomi dan biologi maupun
ilmu-ilmu sosial (termasuk sosiologi dan psikologi),
maupun di bidang bisnis (mengenai produk,
dll), ekonomi,
dan industri.
Statistika juga digunakan dalam pemerintahan untuk
mencapai berbagai macam tujuan; Sensus
populasi masyarakat merupakan salah satu prosedur yang paling
dikenal. Ada pula aplikasi statistika lain yang sekarang populer yaitu
prosedur jajak pendapat atau polling (misalnya
dilakukan sebelum pemilihan umum), serta hitung cepat (perhitungan
cepat hasil pemilu) atau Quick count. Di bidang komputasi,
statistika dapat pula diterapkan dalam pengenalan
pola maupun kecerdasan
buatan ("AI").
didalam statistika terdapat beberapa tools yang dapat digunakan sebagai alat untuk mengolah data statistika diantaranya :
1. SPSS
Tentu Anda sering mendengar program statistika satu ini, di perkuliahan atau pun di beberapa perusahaan besar pun menggunakan software statistika ini. SPSS singkatan dari Statistical Package for the Social Software. Pertama kali dirilis pada tahun 1968 yang dikembangkan oleh Norman H. Nie dan C. Hadlai Hull.
SPSS pertama kalo muncul dengan versi PC dengan nama SPSS/PC+ (versi DOS). Setelah mulai populernya sistem WINDOWS maka SPSS berkembang mulai dari versi 6.0 hingga sekarang. SPSS pada awalnya dibuat untuk keperluan pengolahan data statistik untuk ilmu-ilmu sosial (sesuai dengan singkatan dari SPSS itu sendiri).
SPSS pada tanggal 28 Juli 2009 disebut sebagai PASW (Predictive Analytics SoftWare), karena perusahaan ini telah dibeli oleh perusahaan IBM dengan harga US$ 1,2 milyar. Dan pada Januari 2010 menjadi SPSS : Sebuah Perusahaan IBMΓÇ¥, dan menjadi nama IBM SPSS yang sepenuhnya diintegrasikan ke dalam IBM Corporation dan merupakan salah satu merk dibawah IBM Software Group Portofolio Bisnis Analytics bersama dengan IBM Cognos.
2. MINITAB
Software statistika berikutnya adalah MINITAB yaitu program komputer yang dirancang untuk melakukan pengolahan statistik. Minitab menggabungkan kemudahan penggunaan layaknya Microsoft Excel dengan kemampuannya melakukan analisis statistik yang kompleks.
Minitab dikembangkan di Pennsylvania State University oleh periset Barbara F. Ryan, Thomas A. Ryan, Jr., dan Brian L. Joiner pada tahun 1972. Minitab didistribusikan oleh Minitab Inc, sebuah perusahaan swasta yang bermarkas di State College, Pensylvania dengan kantor cabang Coventry,Inggris (Minitab Ltd) Paris, Perancis (Minitab SARL) dan Sydney, Australia (Minitab Pty.).
Minitab seringkali digunakan dalam perusahaan industri sebagai implementasi Six Sigma ΓÇô TQM, CMMIserta metode perbaikan proses yang berbasis statistik lainnya dikenal dengan Design of Experiment (DOE). Minitab Inc, juga membuat perangkat lunak sebagai pelengkap Minitab 16, Quality Trainer danQuality Companion 3.
3. SAS
SAS adalah singkatan dari Statistical Analysis System yang disediakan oleh SAS Institute Inc. SAS pertama kali dikembangkan oleh Anthony J. Barr pada tahun 1966. Seorang mahasiswa lulusan dari North Carolina State University lulus 1962-1964. SAS menggunakan bahasa pemograman, dan memungkinkan programmer melakukan entri data, analisis statistik, peramalan untuk mendukung keputusan riset operasi, peningkatan kualitas pengembangan aplikasi data dan lain sebagainya. Pemograman dalam SAS dikategorikan dalam 2 jenis, yaitu data step untuk membuat, membaca atau pun memanipulasi data, dan proc step (procedure step) digunakan untuk menganalisa, meringkas atau pun membuat tabulasi dari sebuah data. SAS dibangun sejak versi 6.0 hingga versi 9.2.
Adapun analisa yang dapat dilakukan dengan menggunakan SAS adalah : 1. Base SAS ΓÇô Basic Procedure and Data Management 2. SAS/STAT ΓÇô Statistical Analysis 3. SAS/GRAPH ΓÇô Graphic and presentation 4. SAS/OR ΓÇô Operation research 5. SAS/ETS ΓÇô Econometric and Time Series 6. SAS/IML ΓÇô Interactive matrix language 7. SAS/AF ΓÇô Aplication facility 8. SAS/QC ΓÇô Quality control 9. SAS/INSIGHT ΓÇô Data mining 10. SAS/PH ΓÇô Clinical trial analysis 11. Enterprise Miner ΓÇô Data mining
4. LISREL LISREL adalah software statistik yang ketiga dan paling sering digunakan dalam dunia pendidikan. Singkatan dari LISREL adalahLinear Structural Relationship. Pada awalnya dikembangkan olehKarl Joreskog (1973) yang merupakan sebuah nama model persamaan struktural. Dan selanjutnya dikembangkan software komputer yang mendukungnya oleh Joreskog dan Sorbom. Pertama kali software yang tersedia untuk umum adalah LISREL versi 3 tahun 1975. Dan sekarang sudah mencapai LISREL 8.8. LISREL salah satu software yang digunakan untuk program SEM (Structural Equation Model) yang saat ini masih tercanggih dan dapat mengestimasi berbagai masalah SEM yang bahkan mungkin tidak dapat dilakukan oleh software lainnya. Pada edisi terakhir for windows, LISREL memiliki aplikasi statistik sebagai berikut : 1. LISREL untuk SEM 2. PRELIS untuk manipulasi data dan Analisis statistika dasar 3. MULTILEV untuk hierarchical Linear dan Model nonlinear. 4. SURVEYGLIM untuk GLM (Generalized Linear Modelling). 5. CATFIRM untuk formative inference based recursive modelling for categorical response variables. 6. CONFIRM untuk formative inference based recursive modelling for continuous response variables. 7. MAPGLIM untuk GLM for multilevel data.
5. AMOS
AMOS adalah singkatan dari Analysis of Moment Structure merupakan salah satu software yang digunakan untuk mengestimasi model pada model SEM. AMOS mengimplementasikan pendekatan yang umum untuk analisa data pada model persamaan struktural yang menjelaskan analisa struktur kovarians, atau causal modelling. Pendekatan ini meliputi kasus khusus banyak teknik konvensional terkenal mencakup model linier yang umum dan analisis faktor umum.
AMOS memberikan kemudahan dalam proses perhitungan dan analisis menjadi lebih sederhana bahkan orang-orang awam bukan ahli statistik akan dapat menggunakan dan memahami dengan mudah. AMOS diambil alih oleh Microsoft untuk disesuaikan dengan versi SPSS saat ini.
Metode-metode dalam AMOS saat ini diantaranya : 1. Maximum Likelihood 2. Unweighted Least Square 3. Generalized Least Square 4. BrowneΓÇÖs Asymptotically Distribution ΓÇô Free Criterion 5. Scale Free Least Square
6. EVIEWS EVIEWS singkatan dari Economic Views merupakan perangkat lunak (software) yang banyak digunakan untuk kepentingan analisis data ekonomi dan keuangan. Pada awalnya dikembangkan dan didistribusikan oleh Quantitative Micro Software(QMS). EVIEWS menyajikan perangkat analisis data, regresi dan peramalan (regression and forecasting). EVIEWS dapat memanipulasi data time series. EVIEWS memanfaatkan lingkungan WINDOWS user-friendly dan kegunaan lainnya antara lain analisis data dan evaluasinya, analisis keuangan, peramalan ekonomi makro, simulasi, peramalan penjualan dan analisis biaya.
7. R ΓÇô Software
R adalah software statistik yang bebas (free software) dibawah lisensi GNU (GNU is not unix) General is Public Licence yang menjamin selalu agar R selalu bebas. Lebih tepatnya R bukanlah suatu program statistika, namun sebuah lingkungan pemograman yang banyak digunakan statistisi. R menyediakan penanganan dan penyimpanan data, mendukung banyak operator perhitungan, menyediakan banyak alat untuk analisis data, menampilkan kemampuan graphical yang baik dan merupakan bahasa pemograman langsung yang didasarkan pada bahasa pemograman S yang ditulis oleh Rick Becker, John Chambers, dan Allan Wilks dari AT&T Bell Laboratories. Nama R diambil dari nama depan penulisnya yaitu Ross Ihaka dan Robert Gentlement di Departemen Statistika Universitas Auckland Selandia Baru.
8. STATA
STATA adalah singkatan dari Statistika dan Data yaitu program komputer yang digunakan untuk analisa statistika dan dibuat olehStataCorp tahun 1985. Dirancang untuk keperluan ekonomi, sosiologi dan epidemiologi dengan berbagai fitur manajemen data, analisis statistika, grafik, simulasi dan pemograman.
Untuk mengetahui lebih banyak mengenai STATA silahkan kunjungi di sini.
Masih banyak software statistika lainnya yang biasa digunakan dalam analisis data. Untuk software bisa didownload versi trialnya. Analisis data yang pernah saya gunakan adalah SPSS, MINITAB, AMOS, EVIEWS dan yang paling sering digunakan adalah SPSS dan MINITAB.
Salah satu yang alat bantu dalam pemrosesan data dalam statistika adalah SPSS. SPSS merupakan singkatan dari Statistical Package for Social Sciences. Pertama kali dirilis pada tahun 1968 oleh Norman Nie, seorang lulusan fakultas ilmu politik Standford University, yang sekarang menjadi profesor peneliti fakultas llmu politik di Standford dan profesor emeritus ilmu politik di University of Chicago. Semula SPSS hanya digunakan untuk ilmu sosial saja, tapi perkembangan berikutnya digunakan untuk berbagai disiplin ilmu sehingga kepanjangnya berubah menjadi ΓÇ£Statistical Product and Service SolutionΓÇ¥.
SPSS sebagai sebuah tools mempunyai banyak kelebihan, terutama untuk aplikasi di bidang ilmu sosial. SPSS sering digunakan untuk memecahkan problem riset dan bisnis. Dimana cara kerja yang sederhana, yaitu data yang diinput akan dianalisis berdasarkan metode yang peneliti inginkan. SPSS banyak digunakan oleh peneliti pasar, peneliti kesehatan, perusahaan survey, pemerintah, peneliti pendidikan, organisasi pemasaran, dll. Selain analisis statsitika, manajemen data dan dokumentasi data juga merupakan fitur-fitur dari software dasar SPSS.
Beberapa metode statistik yang termasuk dalam software dasar SPSS diantaranya :
Statistik deskriptif : tabulasi silang, distribusi frekuensi, statistik deskriptif, explorasi.
Statistik bivariat : t-test, ANOVA, korelasi, nonparametric test.
Prediksi hasil numerik : regresi linier
Prediksi untuk mengidentifikasi kelompok : analisis faktor, analisis cluster (two-step, k-means, hierarkis), diskriminan.
Adapun beberapa kemudahan yang lain yang dimiliki SPSS dalam pengoperasiannya adalah karena SPSS menyediakan beberapa fasilitas sebagai berikut :
Data editor. Merupakan jendela untuk pengolahan data. Data editor dirancang sedemikian rupa seperti pada aplikasi-aplikasi spreadsheet untuk mendefinisikan, memasukan, mengedit dan menampilkan data.
Viewer. Viewer mempermudah pemakaian untuk melihat hasil pemrosesan, menunjukkan atau menghilangkan bagian-bagian tertentu dari output, serta memudahkan distribusi hasil pengolahan dari SPSS ke aplikasi-aplikasi yang lain.
Multidimensional pivot tabel. Hasil pengolahan data akan ditunjukkan dengan multidimensional pivot tables. Pemakaian dapat melakukan eksplorasi terhadap tabel dengan pengaturan baris, kolom serta layer. Pemakai juga dapat dengan mudah melakukan pengaturan kelompok data dengan melakukan splitting tabel sehingga hanya satu grup tertentu saja yang ditampilkan pada satu waktu.
High resolution graphics. Dengan kemampuan grafikal beresolusi tinggi baik untuk menampilkan pie chart, bar charts, histogram, scatterplots, 3-D graphics, dll akan membuat SPSS tidak hanya mudah dioperasikan tetapi juga membuat pemakai merasa nyaman dalam pekerjaannya.
Database access. Pemakai program ini dapat memperoleh kembali informasi dari sebuah database dengan menggunakan database wizard yang disediakannya.
Data transformation. Transformasi data akan membantu pemakai memperoleh data yang siap untuk dianalisis. Pemakai dapat dengan mudah melakukan subset data, mengkombinasikan ketegori, add, agregat, merge, split dan beberapa perintah transpose files, serta yang lainnya.
Electronic distribution. Pengguna dapat mengirimkan laporan secara elektronik menggunakan sebuah tombol pengiriman data (email) atau melakukan eksport tabel dan grafik ke mode HTML sehingga mendukung distribusi melalui internet dan intranet.
Online help. SPSS menyediakan fasilitas online help yang akan selalu siap membantu pemakai dalam melakukan pekerjaannya. Bantuan yang diberikan dapat berupa petunjuk pengoperasian secara detail, kemudahan pencarian prosedur yang diinginkan sampai pada contoh-contoh kasus dalam pengoperasian program ini.
Akses data tanpa tempat penyimpanan sementara. Analisis file-file data yang sangat besar disimpan tanpa membutuhkan tempat penyimpanan sementara.
Interface dengan database relasional. Fasilitas ini akan menambah efisiensi dan memudahkan pekerjaan untuk mengekstrak data dan menganalisisnya dari database relasional.
Analisis distribusi. Fasilitas ini diperoleh pada pemakaian SPSS for server atau untuk aplikasi multiuser. Kegunaan dari analisis ini adalah apabila peneliti akan menganalisis file-file data yang sangat besar dapat langsung me-remote dari server dan memprosesnya sekaligus tanpa harus memindahkan ke komputer user.
Multiple sesi. SPSS memberikan kemampuan untuk melakukan analisis lebih dari satu file data pada waktu yang bersamaan.
Mapping. Visualisasi data dapat dibuat dengan berbagai macam tipe baik secara konvensional atau interaktif, misal dengan menggunakan tipe bar, pie atau jangkauan nilai, simbol gradual dan chart.
>> SPSS Evnironment
Data View pada SPSS
Keterangan :
Menu Bar : Kumpulan perintah-perintah dasar untuk mengoperasikan SPSS
Tool Bar : Kumpulan perintah-perintah yang sering digunakan dalam pengoperasian SPSS dalam bentuk gambar atau tampilan pada speadsheet
Column dan row (cell) : Tempat untuk menuliskan data yang akan diolah
Data view : Halaman pengiputan data
Variabel view : Halaman pendefinisian variabel
Name cell (column) : Nama untuk variabel pada setiap cell per column
Data bar : Tempat untuk membantu menuliskan data pada cell
Variabel Views pada SPSS
Keterangan :
Column name : merupakan tempat untuk menuliskan ΓÇ£nama variabel/cellΓÇ¥ per column, hanya boleh satu kata atau menggukan jeda ΓÇ£_ΓÇ¥
Type : menentukan tipe data (numerik, coma, dot, scientific, notation, string, dll)
Width : menentukan jumlah karakter atau angka yang akan tampil dalam data view
Decimals : menentukan jumlah angka di belakan koma
Label : memberikan sebutan atau identitas pada suatu variabel, yang nantinya dalam hasil pengolahan data, nama yang akan muncul adalah nama labelnya.
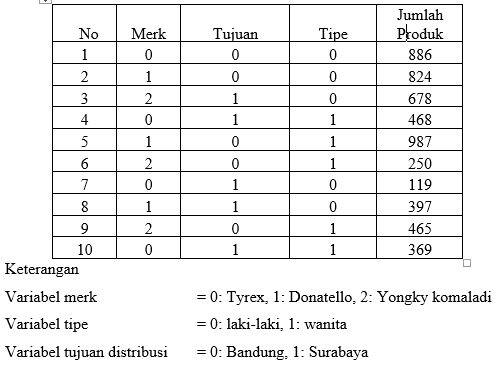
Values : memberikan keterangan ΓÇ£nama atau kategoriΓÇ¥ pengganti pada data variabel, yang ditentukan pada data nominal dan ordinal
Missing : memberikan informasi apabila data tidak ada
Columns : memberikan ukuran lebar column di layar data view
Align : menentukan letak data (rata tengah, kiri atau kanan)
Measure : menentukan jenis skala ukur data yang dimasukan (scale, nominal atau ordinal)
Penting bagi user pemula untuk mengenali interface dari SPSS agar tidak membuat bingung dalam penggunaanya. 2 bagian dari interface SPSS yaitu data view dan variabel view penting untuk diketahui fungsi dan perannya, kedua bagian sengaja dibuat terpisah dikarenakan dalam pengolahan data setelah data dinputkan pada bagian data view maka data tersebut harus didefinisikan didalam variabel view (atau sebaliknya) untuk membantu pengguna memahami konteks data atau variabel secara rule statistiknya sebelum melangkah kepada proses pengolahan data yang ada pada menu bar submenu analysze.
>> Pengoperasian SPSS
Setelah kita menggenal dan mengetahui ruang lingkung software SPSS, akan sangat membantu kita dalam proses penggunaan SPSS untuk keperluan olahdata dari data yang kita miliki. Berikut beberapa tahapan dalam pengoperasian SPSS diantaranya tahapan penginputan data dan tahapan pengolahan data.
Input data manual
Input data manual merupakan penggunaan sheet dari SPSS dengan cara memasukan data secara langsung ke dalam sheet SPSS dengan terlebih dahulu mendefinisikan karekteristik data yang dimiliki pada menu variabel view. Tahapannya adalah sebagai berikut :
Masuk ke variabel View, isi cell name, type, width, dll sesuai dengan ketentuan jenis atau skala ukur dari data yang akan diolah.
Masuk ke data View dan masukan data pada setiap cell sesuai dengan penggolongannya (column)
Data siap di olah sesuai dengan metode statistik yang digunakan
Import database
Fungsi dari import database adalah untuk mengubah file data dari format lain ke dalam format SPSS, yaitu dapat dicontohkan dengan mengubah formal excel ke dalam format SPSS. Tahapannya adalah sebagai berikut :
Pastikan data excel yang akan diimpor, tidak ada baris atau kolom yang tersembunyi (hide)
Buka SPSS
Klik menu File > klik Open > klik Data
Pilih file yang akan dimport
Klik file excel yang akan diimport > klik Open
Data siap diolah sesuai dengan metode statistik yang digunakan
Import Data dalam SPSS
Yang perlu diperhatikan dalam proses penginputan data pada interface data view adalah jenis data dengan skala nominal atau ordinal. Terutama penggunaannya untuk kebutuhan olahdata yang cukup kompleks (cross tabulasi, chi square, regresi dummy atau regresi logistik) untuk menidentifikasi kebutuhan jenis variabel berdasarkan metoda statistik yang digunakan. Cara pertama dengan menginputkan bentuk data text secara langsung harus merubah tipe variabel dalam interface variabel view ΓÇ£typeΓÇ¥ menjadi string bukan numerik sehingga penginputan text pada interface data view memungkinkan secara langsung, selain itu merubah juga fungsi measure (skala ukur) dari scale menjadi nominal atau ordinal. Kedua, dengan mempertahankan inputan data sebagai numerik (baik itu pada data view atau variabel view) akan tetapi menambahkan pada ΓÇ£valuesΓÇÖ berupa kategori dari data numerik yang dinputkan, lalu rubah measure (skala ukur) data yang kita inputkan menjadi nominal atau ordinal.
>> Pengolahan Data SPSS
Pada dasarnya pengolahan data SPSS dapat menggunakan berbagai model statistik yang sesuai dengan kebutuhan. Penggunaan berbagai model statistik dapat diterapkan pada software SPSS dengan menggunakan prosedur pengujian yang telah ditetapkan. Berdasarkan data yang telah diinputkan sebelumnya, maka kita dapat mencoba untuk mengolah menggunakan menu analysis pada SPSS. Tahapannya adalah sebagai berikut :
Buka SPSS
Pilih menu Analyze kemudian pilih menu analisis yang sesuai dengan tujuan olahdata, lalu klik
Isi variabel pada metoda analisis yang dipilih pada bagian kolom keterangan yang tersedia, sesuaikan variabel dengan definisi metode analisis yang dipakai.
Untuk melakukan analisis lengkapi pemrosesan data pada menu-menu yang tersedia pada metode analisis yang dipakai, jika diperlukan. Misal, jika kita menggunakan statistik regresi, apa saja hasil output yang diinginkan maka klik ΓÇÿstatisticsΓÇÖ, ΓÇÿplotsΓÇÖ, ΓÇÿsaveΓÇÖ atau ΓÇÿoptionΓÇÖ.
Setelah proses pemilihan kebutuhan olahdata selesai, klik ΓÇÿOkΓÇÖ maka akan muncul output SPSS.
Menu Analyze pada SPSS
Ouput Analisis pada SPSS
Keunggulan output SPSS adalah kemudahan dalam hal editing ataupun keperluan untuk pembuatan laporan dari hasil olahdata (copy object dan copy). Output SPSS dapat disalin pada aplikasi lain semisal microsoft word atau excel dengan mudah, baik itu berupa gambar ataupun text untuk keperluan editing. Dengan segala kemudahan dan kesederhanaan dalam penggunaanya, SPSS menjadi tools yang banyak dipakai untuk berbagai keperluan analisa, baik itu yang memiliki latarbelakang statistik secara khusus ataupun yang tidak memiliki latar belakang statistik sekalipun dapat dengan mudah menggunakan SPSS sebagai tools pendamping dalam menyelesaiakan olahdata data penelitiannya.
Pada tutorial ini dijelaskan dasar cara memasukkan data dan mengolah data dengan SPSS. Untuk memasukkan data ke SPSS dapat dilakukan secara langsung melalui data view dan variable view. Kemudian akan disimpan dalam format .sav dan .spv (Viewer File).
Contoh:
Nilai ujian statistika dasar mahasiswa suatu kelas adalah 75 87 67 78 89 76 77 88 66 76
A. Cara Memasukkan atau Input Data dengan SPSS
Berikut langkah-langkah sederhana/dasar untuk melakukan input data dengan SPSS,
Buka aplikasi SPSS
Klik All Programs › IBM SPSS Statistics › IBM SPSS Statistics 23. Lokasi shortcut disesuaikan dengan versi SPSS yang terinstall di komputer (versi lain tidak jauh berbeda).
Close dialog Files, karena akan dilakukan analisis data sederhana
Untuk menutup klik (X) pada pojok kiri dialog Files seperti berikut,
Data View: input data melalui lembar kerja dengan tab Data View
Data View adalah tampilan lembar kerja SPSS untuk menampilkan isi dari input data. Data yang dimasukkan diinput secara vertikal. Berikut ilustrasinya,
Perangkat lunak SPSS akan membuat variabel baru dengan VAR00001
Variable View: mengedit dan melihat variabel data pada lembar kerja
Anda dapat mengedit Variable View untuk mengubah nama variabel, tampilan data, type data, panjang tampilan data. Berikut mengubah nama variabel,
Variabel terbentuk menggunakan tipe data (measurement) scale.
Save: Menyimpan data yang telah diinput
Setelah memastikan data terinput benar. Anda dapat menyimpan lembar kerja SPSS dengan klik menu File › Save. Atau menggunakan shortcut keyboard Ctrl+S,
Pilih direktori penyimpanan dan simpan file data dengan nama
Jendela Save Data As akan terbuka untuk menyimpan file data yang telah diinput. Pilih direktori penyimpanan dan simpan file seperti ilustrasi berikut,
Klik Save
File tersimpan
File berhasil disimpan ditandai dengan keluaran berupa jendela output yang menampilkan lokasi penyimpanan, nama file, dan format file yang digunakan. (SAVE OUTFILE)
Anda dapat menutup kedua jendela jika tidak melakukan pekerjaan lainnya.
B. Cara Membuka File SPSS .sav yang Tersimpan
Anda dapat membuka file SPSS dengan format .sav secara langsung untuk mempercepat pekerjaan. Cari file .sav yang tadi tersimpan di direktori anda dan klik 2x file tersebut.
File Nilai.sav akan terbuka disertai dengan output log GET seperti ilustrasi di bawah,
C. Cara Mengolah Data dengan SPSS
Untuk mengolah data sederhana menggunakan SPSS dapat digunakan menu Analyze. Misalkan akan dicari statistika deskriptif dari nilai mahasiswa tersebut.
Sorot nama variabel di kolom kiri dan klik tombol , sehingga nama variabel terlihat di kolom sebelah kanan Variable(s). Seperti berikut,
Klik Options... untuk memilih analisis statistika deskriptif yang akan dihitung
Misalkan dipilih mean (rataan hitung), sum, std. deviation (standar deviasi), variance (variansi), minimum, dan maximum. Klik Continue.
Klik OK pada jendela Descriptives
Hasil analisis ditampilkan pada jendela Output
Terlihat hasil analisis data pada variabel Nilai adalah dengan jumlah data 10 (N), nilai minimum 66, maksimum 89, total nilai 779 (Sum), rata-rata 77.9 (Mean), standar deviasi 8.06157 (Std. Deviation) dan variansi 64.989 (Variance).
Anda dapat menyorot output dan menyalin ke perangkat lunak pengolah kata seperti Microsoft Word.
D. Menyimpan Output Files .spv
Anda dapat menyimpan output files dengan format .spv untuk mempercepat pengulangan eksekusi.
Sorot jendela output
Klik File › Save atau Ctrl+S
Pilih direktori penyimpanan dan simpan output dengan nama
Klik Save
Output file tersimpan dengan format .spv (Viewer File)
Untuk tugas pertemuan minggu pertama kalian diwajibkan menginstal spps pada layar laptop masing-masing dan hasilnya di screen shot dan di tempel pada word yang di konversi menggunakan pdf,, jangan lupa pada lembar jawaban di tulis nama dan npm
Analisis frekuensi merupakan analisis yang mencakup gambaran frekuensi data secara umum seperti mean, media, modus, deviasi, standar, varian, minimum, maksimum dan sebagainya. Analisi ini juga masuk pada jenis analisis deskriptif. Data yang dipakai untuk statistik deskriptif bisa kualitatif dan kuantatif.
Misalkan dibuat tabel frekuensi beserta histogram dari nilai praktikum komputer yang diperoleh 17 mahasiswa yaitu 78 78 81 76 84 94 78 76 78 82 81 88 93 93 81 76 78. Berikut langkah-langkahnya,
A. Cara Membuat Tabel Distribusi Frekuensi dengan SPSS
Membuat Variabel Data
Dari data kasus yang terkumpul dapat kita ketahui data menggunakan pengukuran scale (skala) dan dengan type numeric. Sehingga dapat dibuat variabel baru dengan nama 'nilai' dengan label 'Nilai Praktikum'.
Buka aplikasi SPSS Statistics dan arahkan ke Variable View
Sorot sel pertama
Klik Edit › Insert Variable
Sunting variabel dengan konfigurasi di atas
Input Data melalui Data View
Setelah variabel nilai dibuat, data kasus dapat dimasukkan melalui Data View. Kasus yang ada di variabel baris pertama di Variable View, dapat diinput melalui kolom pertama di Data View.
Untuk mempermudah membaca visualisasi data dapat dibuat tabel frekuensi beserta histogram data. Berikut langkah-langkahnya,
Klik menu bar Analyze › Descriptive Statistics › Frequencies...
Pilih variabel yang dilakukan analisis frekuensi
Setelah jendela Frequencies terbuka, pilih nama variabel yang akan dianalisis frekuensinya. Hal ini dilakukan dengan memindahkan variabel di kolom kiri ke kolom kanan.
Menambahkan Histogram, klik Charts... pada jendela Frequencies
Sehingga terbuka jendela Frequencies: Charts, pilih Histogram dan klik Continue.
Klik OK
Tunggu hingga jendela output dari tabel distribusi frekuensi dan histogram terbuka.
Selesai
B. Membaca Tabel Distribusi Frekuensi dan Histogram SPSS
Berikut ilustrasi jendela output frekuensi dari variabel nilai,
HASIL ANALISA
hasil analisa sangat penting bagi mahasiswa yang mempelajari aplikasi statistikan, untuk analisa wajib di tulis baik di ms word kertas sesuai dengan kebutuhan dan seluruh data yang ada di dalam tabel frequensi harus di analisa..berikut contoh analisa tabel frekuensi
Berdasarkan tabel frekuensi nilai praktikum untuk nilai praktikum sebesar 76 benyak 3 buah dengan tingkat frekuensi berjumlah 17,6% dari total keseluruhan responden dan seterusnya di jelaskan satu-per satu sampai dengan nilai 94
Crosstab/Cross Tabulation (Tabulasi Silang) atau yang juga biasa disebut Tabel Kontigensi merupakan salah satu bentuk analisis deskriptif yang menggabungkan lebih dari satu variabel kedalam bentuk tabel. Crosstab bertujuan untuk meringkas informasi dari sekumpulan data kedalam bentuk tabel. Crosstab juga mempermudah pembaca dalam memahami kriteria data.
Crosstab dapat dibuat menggunakan software aritmatika pada umumnya seperti Microsoft Excel, namun membutuhkan banyak waktu untuk memahami maksud data dan mengolahnya kedalam bentuk Crosstab. Penggunaan software SPSS (Statistical Package for the Social Science) lebih direkomendasikan karena cara penggunaannya yang simpel dan menghasilkan output yang mudah dibaca atau dipahami. Oleh karena itu pada artikel kali ini kita akan membahas cara membuat Crosstab beserta penjelasan hasilnya.
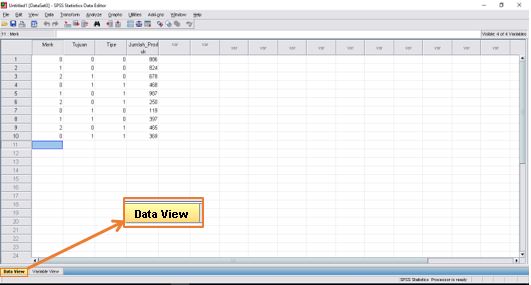
Sebagai latihan, kita akan menggunakan contoh data sebagai berikut:
Data Studi Kasus
1. Buka aplikasi SPSS
Setelah lembar kerja SPSS terbuka, klik variable view yang ada di posisi pojok kiri bawah. Variable view ini berguna untuk mendefinisikan variabel yang akan dimasukkan.
Membuka Variabel View
2. Mendefinisikan Variabel
Masukkan definisi variabel satu persatu. Dimulai dari variabel Merk dengan ketentuan sebagai berikut:
Name: Merk (Nama variabel yang anda inginkan)
Type: Numeric (Pemilihan tipe tulisan. Pada kasus ini tulisan bersifat numerik)
Width: 8 (Banyaknya angka yang dikehendaki dalam satu baris)
Decimal: 0 (Banyak bilangan desimal yang diinginkan)
Label: *Dikosongkan saja
Missing: None (Nilai missing values yang dikehendaki)
Columns: 8 (Banyaknya angka yang dikehendaki dalam satu kolom. Biasanya Width = Columns)
Align: Right (Penyetaraan tulisan)
Measure: Scale (Pemilihan tipe data. Pada kasus ini data bersifat skala)
Values: Pada bagian values, klik pada bagian "titik tiga" seperti pada gambar dibawah.
Memasukkan Kriteria Nilai Value
Sehingga akan muncul kotak dialog Value Labels untuk memasukkan nilai Values. Masukkan nilai Value = 0 dan Label = Tyrex, kemudian klik Add. Seperti pada contoh gambar dibawah.
Kotak Dialog Value Labels
Setelah itu masukkan juga nilai Value = 1 dengan Label = Donatello, serta Value = 2 dengan Label = Yongky Komaladi. Hal ini sesuai dengan ketentuan studi kasus apabila merk sepatunya Tyrex maka akan diberikan kode 0, merk Donatello dengan kode 1, dan merk Yongky Komaladi dengan kode 2.
Kota Dialog Value Labels yang Sudah Terisi
Jika sudah, selanjutnya memasukkan variabel Tujuan, dengan ketentuan sebagai berikut:
Name: Tujuan (Nama variabel yang anda inginkan)
Type: Numeric (Pemilihan tipe tulisan. Pada kasus ini tulisan bersifat numerik)
Width: 8 (Banyaknya angka yang dikehendaki dalam satu baris)
Decimal: 0 (Banyak bilangan desimal yang diinginkan)
Label: *Dikosongkan saja
Missing: None (Nilai missing values yang dikehendaki)
Columns: 8 (Banyaknya angka yang dikehendaki dalam satu kolom. Biasanya Width = Columns)
Align: Right (Penyetaraan tulisan)
Measure: Scale (Pemilihan tipe data. Pada kasus ini data bersifat skala)
Values: 0 = Bandung, 1 = Surabaya (Masukkan nilainya dengan cara yang sama seperti pada variabel Merk)
Type: Numeric (Pemilihan tipe tulisan. Pada kasus ini tulisan bersifat numerik)
Width: 8 (Banyaknya angka yang dikehendaki dalam satu baris)
Decimal: 0 (Banyak bilangan desimal yang diinginkan)
Label: *Dikosongkan saja
Missing: None (Nilai missing values yang dikehendaki)
Columns: 8 (Banyaknya angka yang dikehendaki dalam satu kolom. Biasanya Width = Columns)
Align: Right (Penyetaraan tulisan)
Measure: Scale (Pemilihan tipe data. Pada kasus ini data bersifat skala)
Values: 0 = Laki-laki, 1 = Wanita (Masukkan nilainya dengan cara yang sama seperti pada variabel Merk)
Variabel Jumlah Produk:
Name: Jumlah_Produk (Nama variabel yang anda inginkan. SPSS tidak bisa membaca data spasi, maka gunakan under score ( _ ) untuk menggantikan fungsi spasi)
Type: Numeric (Pemilihan tipe tulisan. Pada kasus ini tulisan bersifat numerik)
Width: 8 (Banyaknya angka yang dikehendaki dalam satu baris)
Decimal: 0 (Banyak bilangan desimal yang diinginkan)
Label: *Dikosongkan saja
Missing: None (Nilai missing values yang dikehendaki)
Columns: 8 (Banyaknya angka yang dikehendaki dalam satu kolom. Biasanya Width = Columns)
Align: Right (Penyetaraan tulisan)
Measure: Scale (Pemilihan tipe data. Pada kasus ini data bersifat skala)
Values: None (Karena tidak ada yang perlu didefinisikan pada variabel jumlah produksi)
Nantinya semua variabel yang telah didefinisikan akan terlihat seperti ini:
Mendefinisikan Variabel
3. Memasukkan Data
Berpindahlah ke sheet Data View yang ada disebelah tulisan Variable View. Masukkan data satu persatu sesuai dengan ketentuan studi kasus. Jika data anda ada banyak dan tersimpan di file Microsoft Excel, maka anda bisa meng-copy dari Excel kemudian paste-kan kedalam lembar kerja SPSS. Namun lakukan copy paste data harus berdasarkan pervariabel.
Memasukkan Data ke Data View
4. Tahap Analisis Data
Klik Analyze → klik DescriptiveStatistic → klik Crosstab. Setelah mengklik Crosstab maka akan muncul kotak dialog Crosstabs. Masukkan variabel merk ke kotak row(s), tipe ke kotak column(s) dan tujuan ke kotak layer dengan cara mengklik nama masing-masing variabel kemudian klik tanda panah yang berwarna biru. Setelah itu klik OK maka hasilnya akan keluar pada lembar output SPSS.
Kotak Dialog Crosstab
5. Hasil Analisis dan Pembahasan
CARA ANALISA.. HASIL ANALISA HARUS DI TULIS BAIK DI WORD MAUPUN DI KERTAS
berdasarkan hasil analisis crosstab didapatkan informasi untuk pengiriman sepatu dengan tujuan bandung dengan merek tyrex untuk tipe laki-laki sebanyak 886 dan tipe wanita sebanyak 0 dengan total keseluruhan pengiriman sebanyak 886
berdasarkan hasil analisis crosstab didapatkan informasi untuk pengiriman sepatu dengan tujuan bandung dengan merek donatelo untuk tipe laki-laki sebanyak 824 dan tipe wanita sebanyak 987 dengan total keseluruhan pengiriman sebanyak 1811
begitu seterusnya sampai dengan penjelasan surabaya dengan tipe sepatu yongki komaladi
JENIS-JENIS GRAFIK DAN CARA MEMBUAT GRAFIK MENGGUNAKAN SPSS
Diagram batang
Untuk membuat diagram batang di SPSS dapat dilakukan dengan beberapa langkah yang harus dilakukan adalah :
Buka file yang akan dibuat menjadi diagram garis pada contoh berikut merupakan data Jumlah rumah tangga dengan kepala rumah tangga perempuan usia 60 Tahun ke atas di beberapa provinsi (Jumlah rumah tangga dengan Kepala Rumah Tangga Perempuan menurut kelompok umur kepala rumah tangga dengan status kesejahteraan 40% terendah di Indonesia. Sumber: Data Terpadu Program Penanganan Fakir Miskin (TNP2K))
Pada SPSS terdapat colomn Data view untuk tempat munculnya data dan variable view untuk nama setiap variable, menentukan skala data dll
Klik Graphs pada toolbar menu Legacy Dialogs Bar simple values of individual cases Define seperti pada gambar dibawah ini
Pada Bars Represent isikan variebl yang berupa data numeric
Pada category labels klik variable yang berupa data string
Klik ok
Diagram garis
Untuk membuat diagram garis di SPSS dapat dilakukan dengan beberapa langkah yang harus dilakukan adalah :
Buka file yang akan dibuat menjadi diagram garis pada contoh berikut merupakan data Jumlah rumah tangga dengan kepala rumah tangga perempuan usia 60 Tahun ke atas di beberapa provinsi (Jumlah rumah tangga dengan Kepala Rumah Tangga Perempuan menurut kelompok umur kepala rumah tangga dengan status kesejahteraan 40% terendah di Indonesia. Sumber: Data Terpadu Program Penanganan Fakir Miskin (TNP2K))
Pada SPSS terdapat colomn Data view untuk tempat munculnya data dan variable view untuk nama setiap variable, menentukan skala data dll
Klik Graphs pada toolbar menu Legacy Dialogs Line simple values of individual cases Define seperti pada gambar dibawah ini
Pada Bars Represent isikan variebl yang berupa data numeric
Pada category labels klik variable yang berupa data string
Klik ok
Pie Chart
Untuk membuat pie chart di SPSS dapat dilakukan dengan beberapa langkah yang harus dilakukan adalah :
Buka file yang akan dibuat menjadi diagram garis pada contoh berikut merupakan data Jumlah rumah tangga dengan kepala rumah tangga perempuan usia 60 Tahun ke atas di beberapa provinsi (Jumlah rumah tangga dengan Kepala Rumah Tangga Perempuan menurut kelompok umur kepala rumah tangga dengan status kesejahteraan 40% terendah di Indonesia. Sumber: Data Terpadu Program Penanganan Fakir Miskin (TNP2K))
Pada SPSS terdapat colomn Data view untuk tempat munculnya data dan variable view untuk nama setiap variable, menentukan skala data dll
Klik Graphs pada toolbar menu Legacy Dialogs Pie values of individual cases Define seperti pada gambar dibawah ini
Pada Bars Represent isikan variebl yang berupa data numeric
Pada category labels klik variable yang berupa data string
Klik ok
Scatter plot
Untuk membuat scatter plot di SPSS dapat dilakukan dengan beberapa langkah yang harus dilakukan adalah :
Buka file yang akan dibuat menjadi diagram garis pada contoh berikut merupakan data Jumlah rumah tangga dengan kepala rumah tangga perempuan usia 60 Tahun ke atas di beberapa provinsi (Jumlah rumah tangga dengan Kepala Rumah Tangga Perempuan menurut kelompok umur kepala rumah tangga dengan status kesejahteraan 40% terendah di Indonesia. Sumber: Data Terpadu Program Penanganan Fakir Miskin (TNP2K))
Pada SPSS terdapat colomn Data view untuk tempat munculnya data dan variable view untuk nama setiap variable, menentukan skala data dll
Klik Graphs pada toolbar menu Legacy Dialogs Scatter/Dot simple scatter Define seperti pada gambar dibawah ini
Pada Y Axis dan X Axis harus berisikan data numerik
Statistik selalu digunakan ketika parameter yang menggambarkan karakteristik populasi tidak diketahui. Statistik akan mengambil sebagian (kecil) dari populasi untuk dilakukan pengukuran, kemudian hasil pengukuran tersebut dijadikan sebagai kesimpulan ikterhadap keseluruhan populasi. Sebagian (kecil) dari populasi tersebut dinamakan sampel. Ibarat kita ingin mengetahui rasa sepanci sayur asem, kita tidak perlu menenggak satu panci tapi cukup mencicipinya sebanyak satu sendok.
Terdapat dua jenis statistik yang digunakan ketika penelitian, yaitu:
Statistik deskriptif (descriptive statistics), yang hanya menggambarkan data atau seperti apa data ditunjukkan.
Statistik inferensi(inferential statistics), yang mencoba untuk mencapai kesimpulan (bersifat induktif) dari data dengan kondisi yang lebih umum (Trochim, 2006), misal: point estimation, confidence interval estimation, hypothesis testing.
Definisi lengkap statistik deskriptif adalah metode-metode yang berkaitan dengan pengumpulan dan penyajian suatu gugus data sehingga menaksir kualitas data berupa jenis variabel, ringkasan statistik (mean, median, modus, standar deviasi, etc), distribusi, dan representasi bergambar (grafik), tanpa rumus probabilistik apapun (Walpole, 1993; Correa-Prisant, 2000; Dodge, 2006).
Tabel 1 Data Nilai Mahasiswa (bukan data sebenarnya)
Nama
Usia
Jenis Kelamin
Nilai APK
Nilai PPC
Nilai PLO
Suhairi
20
Laki-Laki
80
50
70
Ambon
21
Laki-Laki
70
70
90
Astri
22
Perempuan
60
80
70
Henri
21
Laki-Laki
80
90
60
Yugos
22
Laki-Laki
90
60
70
Muji
19
Perempuan
70
80
80
Tatang
20
Laki-Laki
60
70
40
Ferdi
21
Laki-Laki
60
90
60
Arsyad
21
Laki-Laki
70
70
40
Fauzan
21
Laki-Laki
90
80
60
*) Laki-Laki (Value: 1), Perempuan (Value: 2)
Entry Data
Langkah pertama yang perlu dilakukan adalah meng-entry data, tentunya anda perlu paham dasar-dasar SPSS (silahkan baca posting sebelumnya yang berjudul: Dasar-Dasar SPSS). Entry data dilakukan pada tab sheetData View setiap baris mewakili satu responden, sedangkan setiap kolom mewakili satu variabel, dalam kasus ini variabelnya adalah: Nama, Usia, Jenis Kelamin, Nilai APK, Nilai PPC, dan Nilai PLO.
Berikut langkah-langkah entry datanya:
(1) Pada tab[Variable View], isi kolom Name dengan variabel:
Nama untuk ΓÇ£NamaΓÇ¥
Usia untuk ΓÇ£UsiaΓÇ¥
Gender untuk ΓÇ£Jenis KelaminΓÇ¥
APK untuk ΓÇ£Nilai APKΓÇ¥
PPC untuk ΓÇ£Nilai PPCΓÇ¥
PLO untuk ΓÇ£Nilai PLOΓÇ¥
(2) Isi kolom Label:
Usia
Jenis Kelamin
Nilai APK
Nilai PPC
Nilai PLO
Hal ini berarti: variabel Gender mempunyai label ΓÇ£Jenis KelaminΓÇ¥, variabel APK mempunyai label ΓÇ£Nilai APKΓÇ¥, dan seterusnya.
(3) Isi kolom Values untuk variabel Gender:
Value: 1 = Laki-laki dan
Value: 2 = Perempuan.
(4) Ubah kolom Type untuk variabel Nama menjadi String.
(5) Isi kolom Decimals dengan 0 (nol) untuk semua variabel.
(6) Biarkan default SPSS untuk kolom Width, Missing, dan Columns.
(7) Jangan lupa ΓÇ¥saveΓÇ¥ atau tekan Ctrl + S.
Gambar 1. Entry Variabel pada Tab Sheet Variable View
(8) Pada tab[Data View], isi data seperti Gambar 2 di bawah ini.
Gambar 2. Entry Data pada Tab Sheet Data View
Langkah-langkah uji analisis Descriptives
Dengan menggunakan data sebelumnya langkah-langkah perintah Descriptives adalah sebagai berikut:
(1) Klik menu [Analyze] -> [Descriptives Statistics] -> [Descriptives], muncul dialog boxDescriptives.
(2) Masukkan variabel yang akan dianalisis ke form Variables(s).
(3) Klik [Options] untuk melakukan setting optional, muncul dialog boxDescriptives: Options.
(4) Centang analisis yang diperlukan, saya memilih:
Mean
Std. deviation
Minimum
Maximum
Kurtosis
Skewness
(5) Centang Variable list pada form Display Order.
Gambar 9. Langkah-Langkah Descriptives Statistics
(6) Klik [Continue] dan [OK]. Hasil analisis akan terlihat seperti tabel yang ditunjukkan Gambar 10 di bawah ini:
Gambar 10. Output Descriptives
Untuk analisis data sebagai berikut :
1. Berdasarkan tabel deskriptif yang dihasilkan untuk variabel usia dengan jumlah total keseluruhan data sebanyak 10 dengan usia minimum 19 dan usia maksimum 22 dengan rata rata usia sebesar 20.80. Standar deviasi variabel usia sebesar 0.919 serta nilai skewneess dan kurtosis sebesar -0.601 dan 0.396
begitu seterusnya dijelaskan sampai dengan nilai total
STATISTIK PARAMETRIK : UJI T
SPSS merupakan software yang dikhususkan untuk membuat analisis statistik. Dengan
SPSS memungkinkan untuk melakukan berbagai uji statistik parametrik salah satunya uji-t.
Uji-t berguna untuk menilai apakah mean dan keragaman dari dua kelompok berbeda
secara statistik satu sama lain.
Bagian ini meliputi:
1. One-Sample T Test
2. Independent-Sample T Test
3. Paired-Sample T Test
untuk kesimpulan uji kita dapat menggunakan kriteria jika :
1. Sig< Alpha (0.05) = H0 ditolak menerima H1
2. Sig>Alpha (0.05) = H0 diterima dan menolak H1
atau
1. T hitung > T tabel = H0 ditolak menerima H1
2. T hitung < T tabel = H0 diterima dan menolak H1
Uji korelasi merupakan salah satu uji statistik yang digunakan untuk mengetahui keeratan hubungan variabel bebas dan variabel tidak bebas. Dalam artikel kali ini akan membahas tentang pengujian korelasi menggunakan aplikasi SPSS
Uji korelasi merupakan pengujian atau analisis data yang berfungsi untuk mengetahui tingkat keeratan hubungan antara variabel bebas (X) dan variabel tidak bebas (Y). Dalam uji ini, pengujiannya hanya untuk mengetahui hubungannya saja. Bentuk hubungan yang dimaksud adalah mengetahui sifat hubungan variabel X dan Y, bentuknya yaitu :
Apabila sifat hubungannya positif, artinya jika variabel X naik, maka variabel Y juga naik.
Apabila sifat hubungannya negatif, artinya jika variabel X naik, maka variabel Y turun. Jadi, kebalikannya atau memiliki arah yang berlawanan.
Apabila kedua variabel tidak memiliki hubungan, maka nilainya akan menunjukkan angka 0 (nol).
Dalam setiap pengujian statistik pasti memiliki syarat atau kriteria pengujian yang digunakan untuk menginterpretasikan atau menjabarkan arti dari nilai-nilai yang diperoleh saat pengujian. Dalam uji korelasi terdapat tiga cara untuk mengetahui hubungan antara variabel X dan Y, yaitu :
Melihat dari rhitung, caranya dengan membandingkan rhitung dengan rtabel. Apabila rhitung > rtabel maka H0 ditolak artinya kedua variabel memiliki hubungan. Apabila rhitung < rtabel maka H0 diterima artinya kedua variabel tidak memiliki hubungan.
Melihat dari nilai signifikansinya. Caranya apabila nilai signifikansi variabel < 0,05 artinya terdapat hubungan secara signifikan antara kedua variabel. Apabila > 0,05 artinya tidak terdapat hubungan secara signifikan antara kedua variabel.
Melihat nilai Pearson Correlation. Apabila nilainya sama dengan 0 (nol), maka kedua variabel tidak terdapat hubungan. Sebaliknya, Apabila nilainya tidak sama dengan 0 (nol), maka kedua variabel terdapat hubungan.
Untuk mengenai arti dan arah hubungan dari nilai korelasi variabel X dan Y. Penjelasannya sebagai berikut:
Mengenai arah hubungannya
Mengartikan arah hubungan kedua variabel dapat dilihat dari apakah angka tersebut memiliki tanda posisif atau negatif. Apabila tandanya negatif, artinya variabel X naik maka variabel Y turun atau sebaliknya, jadi berlawanan arah. Namun apabila tandanya positif, artinya variabel X naik maka variabel Y juga ikut naik, satu arah.
Mengenai kekuatan hubungannya
Dalam uji korelasi, penentuan kuat atau lemahnya suatu hubungan dinilai dari apabila nilai tersebut mendekati angka 1 atau -1. Jika angka yang diperoleh mendekati angka 0, maka hubungan kedua variabel dapat dikatakan lemah.
Dalam uji korelasi terdapat beberapa pengujian yang dapat digunakan yaitu Pearson, KendalΓÇÖs, dan Spearman. Nah, dalam artikel ini saya akan menjelaskan bagaimana pengujian Korelasi Pearson. Pengujian korelasi pearson digunakan untuk menguji data yang berskala interval/rasio dan hanya digunakan untuk pengujian sederhana atau hanya untuk mengetahui hubungan antar dua variabel saja (variabel X dan Y).
Pengujian Menggunakan SPSS
Selanjutnya, kamu akan mempelajrai bagaimana pengujian korelasi pearson menggunakan aplikasi SPSS. Versi SPSS yang saya gunakan adalah versi 22. Sebelum dimulai, silahkan persiapkan data yang ingin kamu uji terlebih dulu. Atau sebagai bahan latihan, kamu bisa menggunakan data dibawah.
Cara pengujiannya, sebagai berikut:
Buka aplikasi SPSS. pada ΓÇÿVariable ViewΓÇÖ silahkan atur karakter data terlebih dulu. Misalnya seperti ini.
Sumber : Dokumentasi Penulis
2. Lalu, masukkan data di ΓÇÿData ViewΓÇÖ sesuai kolom variabel yang sudah dibuat.
Sumber : Dokumentasi Penulis
3. Klik menu Analyze > Correlate > Bivariate
Sumber : Dokumentasi Penulis
4. Maka akan muncul kotak dialog. Lalu, pindahkan variabel X dan Y ke kotak ΓÇÿVariablesΓÇÖ. Pada ΓÇÿCorrelation CoefficientsΓÇÖ centang ΓÇÿPearsonΓÇÖ. Pada ΓÇÿTest of SignificanceΓÇÖ centang ΓÇÿTwo-TailedΓÇÖ dan terakhir centang ΓÇÿFlag significant correlationsΓÇÖ. Lalu, klik OK.
Sumber : Dokumentasi Penulis
5. Selanjutnya akan muncul hasilnya. Perhatikan pada kota ΓÇÿCorrelationsΓÇÖ.
Sumber : Dokumentasi Penulis
Interpretasi Uji Korelasi ΓÇô Pearson
Setelah melakukan pengujian menggunakan SPSS, selanjutnya hasil yang diperoleh lalu diinterpretasikan supaya tahu apakah data yang di uji korelasi memiliki hubungan atau tidak. Saya akan menjelaskan interpretasi dari uji korelasi yang caranya membandingkan nilai rhitung dan juga menginterpretasikan nilai signifikansinya.
Membandingkan rhitung dengan r
Pertama, mencari nilai rtabel terlebih dulu. Sesuaikan dengan ketentuan df(N-2, 0,05). ΓÇÿNΓÇÖ merupakan jumlah data sampel yang diuji. Setelah dimasukkan ke rumus, lalu mencari nilai rtabel di data tabel r.
rtabel = df(15-2, 0,05) = 0,514
Sumber : Dokumentasi Penulis
Kedua, bandingkan rhitung dengan rtabel lalu interpretasikan sesuai kriteria pengujian.
Diketahui rhitung = 0,425 dan rtabel = 0,514.
0,425 < 0,514 maka H0 ditolak artinya antara variabel X dan Y tidak terdapat hubungan positif.
Melihat nilai signifikansinya
Diketahui nilai signifikansi (2-tailed) sebesar 0,114.
0,114 > 0,05 artinya antara variabel X dan Y tidak terdapat hubungan yang signifikan.
Uji korelasi merupakan uji statistik yang hanya untuk mengetahui apakah ada hubungan antara dua variabel atau lebih dari penelitian atau seberapa besar hubungan antar variabel penelitian. Dari penjelasan diatas, kamu sekarang sudah bagaimana teori, cara pengujian, kriteria pengujian dan interpretasi dari uji korelasi.
Pengujian menggunakan program SPSS digunakan untuk mencari nilai hitung atau statistik untuk selanjutnya diinterpretasikan untuk pengampilan keputusan penelitian. Dari contoh kasus diatas dapat disimpulkan bahwa antara variabel Stress Kerja (X) dengan variabel Prestasi Guru (Y) tidak memiliki hubungan satu sama lain.
Regresi linier sederhana adalah suatu metode yang digunakan untuk melihat hubungan antar satu variabel independent (bebas) dan mempunyai hubungan garis lurus dengan variabel dependennya (terikat). Sebuah variabel hasil observasi yang diperoleh sangat mungkin dipengaruhi oleh variabel lainnya, misalkan tinggi badan dan berat badan seseorang. Untuk suatu tinggi tertentu ada besaran berat badan yang mempengaruhi, demikian juga sebaliknya. Contoh lain misalnya produksi padi yang dipengaruhi oleh luas lahan yang ditanami, jenis pupuk yang dipakai, banyaknya pupuk yang dipakai dll.
Namun kenyataanya hubungan antar variabel bebas dan variabel terikat jarang sekali sesederhana itu. Biasanya banyak faktor atau dalam hal ini kita sebut banyak variabel bebas yang menentukan atau dapat mempengaruhi variabel terikat. Untuk kasus demikian maka akan diselesaikan dengan Regresi Linier Berganda
Contoh lain, Seorang guru ingin meramalkan nilai prestasi belajar siswa tingkat persiapan pada suatu pokok bahasan, untuk membuat peramalan semacam ini, pertama-tama kita perhatikan dulu sebaran nilai pada materi yang pernah diperoleh siswa pada tahun sebelumnya, kemudian kita melambangkan nilai seseorang siswa dengan variabel tak bebas Y dan nilai prestasi belajar siswa kita lambangkan dengan variabel bebas X. Setelah di dapat nilai variabel tak bebas Y dan variabel bebas X, kemudian data tersebut dapat kita tebarkan dalam bentuk diagram pencar, dengan mengamati diagram pencar terlihat bahwa titik-titiknya mengikuti suatu garis lurus yang menunjukkan kedua peubah X dan Y saling berhubungan secara linear yang ditunjukkan seperti gambar berikut:
Dalam hal ini kita dapat menyatakan secara matematik dengan sebuah persamaan garis lurus yang disebut garis regresi linear. Sebuah garis lurus dapat ditulis dalam bentuk:
Y = a + bx
Dari persamaan garis di atas dalam hal ini Y digunakan untuk membedakan antara nilai ramalan yang didapat dari garis regresi dan nilai pengamatan Y yang sesungguhnya untuk nilai x tertentu, sedangkan a dapat dinyatakan sebagai intercept atau perpotongan dengan sumbu tegak, dan b itu kemiringan garis yang dikalikan dengan nilai x lalu ditambahkan dengan nilai a yang bertujuan untuk meramalkan nilai Y yang berpadanan pada suatu nilai x tertentu.
Sebelum kita mengaplikasikan dengan SPSS, hal yang harus kita ketahui bahwa regresi linear itu sendiri dibagi menjadi beberapa bagian, yaitu yang pertama regresi linear sederhana atau yang dikenal dengan regresi linear hanya ada satu variabel bebas (independent), yang kedua regresi linear berganda yaitu regresi linear yang lebih dari satu variabel bebas (independent) dan masih ada yang lain yang tidak disebutkan di sini, itu nanti kita bahas di artikel yang lain. Namun pada artikel kali ini kita akan mengaplikasikan kasus regresi linear sederhana menggunakan SPSS.
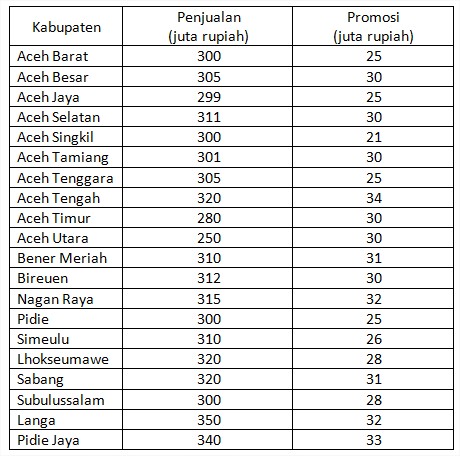
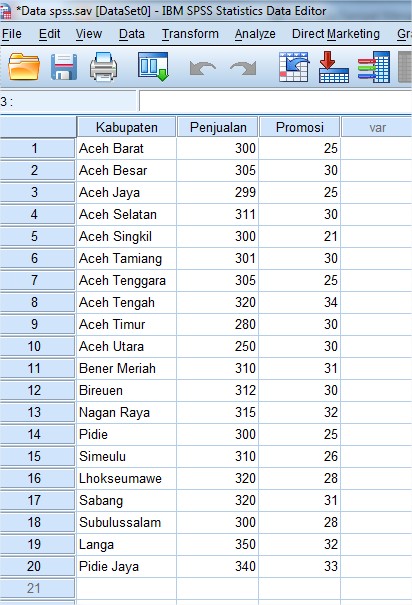
Contoh: PT. Ubey Motor dalam beberapa bulan terakhir ini mengalami penurunan penjualan secara drastis terhadap motor jenis A, oleh sebab itu kepala pemasaran melakukan terobosan baru dengan cara memberlakukan promosi khusus dengan harapan dapat meningkatkan daya beli masyarakat. Promosi dilakukan pada 20 cabang yang tersebar di provinsi Aceh. Berikut data total penjualan dan biaya promosi yang dikeluarkan pada 20 cabang PT Ubey Motor tersebut.
Data di atas merupakan hasil penjualan dalam satu bulan terakhir setelah melakukan promosi. Kemudian kepala pemasaran PT tersebut ingin mengetahui seberapa jauh biaya promosi berpengaruh terhadap penjualan atau seberapa besar hubungannya. Oleh karena itu dalam hal ini kita akan menggunakanj uji regresi sederhana, karena hanya ada satu variabel bebas (independent) yaitu promosi dan satu variabel terikat (dependent) yaitu penjualan.
Berikut langkah-langkah menggunakan SPSS 1. Buka aplikasi SPSS yang telah di install sebelumnya sampai muncul area kerja berikut
2. Pada pojok kiri bawah dari gambar di atas klik Variable View dan buat variabel dari data seperti gambar berikut:
3. Bila sudah di isi semua variable view seperti gambar di atas, selanjutnya klik Data View ada pada sebelah kiri Variable view untuk kita isi data kabupaten, hasil penjualan dan biaya promosi seperti gambar berikut:
4. Selanjutnya pilih menu Analyze --- > Regression ---> Linear. bila sudah maka terlihat seperti gambar berikut:
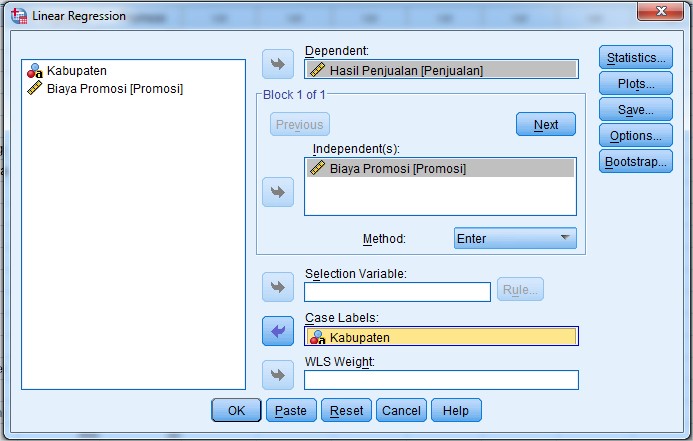
5. Pindahkan variabel Hasil Penjualan [Penjualan] ke dalam kotak Dependent 6. Pindahkan variabel Biaya Promosi [Promosi] ke dalam kotak Independet 7. Pindahkan variabel Kabupaten ke dalam kotak Case Labels 8. jika sudah terlihat seperti gambar berikut:
9. Selanjutnya klik Options (biasa sudah terisi secara default) bila belum dapat di isi seperti berikut:
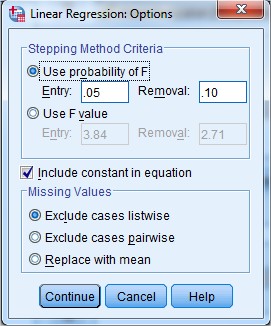
10. Dari gambar di atas dapat kita ketahui bahwa pada kotak Stepping Method Criteria kita menggunakan uji F dengan taraf kepercayaan 5% atau nilai probabilitas 0.05 yang terdapat pada kotak Entry. Biarkan secara default yaitu include constant in equation. Pada kotak Missing Values biarkan secara default yaitu Exclude cases listwise kegunaannya untuk penanganan missing value atau tidak ada data yang hilang. Selanjtnya klik Continue maka akan kembali ke gambar seperti pada langkah 8
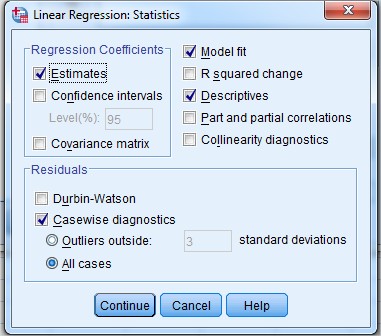
11. Selanjtnya klik Statistik, lalu centang apa yang terlihat seperti pada bambar berikut:
12. Dari gambar di atas, pada kotak Regression Coefficients biasanya secara default sudah tercentang Estimates, karena ini perlakuan koefesien regresi untuk mengestimasi variabel. sedangkan centang model fit berguna untuk mecocokkan model regresi, dan centang Descriptives untuk mengetahui deskriptive dari data. Pada kotak Residuals centang Casewise diagnostics dan pilih All cases yang berfungsi untuk melihat pengaruh regresi terhadap hasil penjualan dan biaya promosi dari semua kabupaten. Selanjtnya klik Continue maka akan kembali ke gambar seperti pada langkah 8.
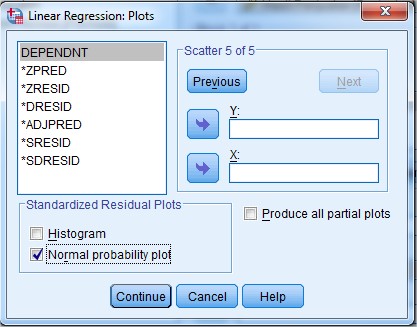
13. Selanjtnya klik Plot. maka muncul seperti gambar berikut:
14. Dari gambar di atas, merupakan tampilan plot dapat digunakan untuk menguji asumsi-asumsi pada regresi, seperti uji normalitas, uji linieritas, dan uji kesamaan varians dari variabel.
Kemudian klik SDRESID lalu pindahkan ke dalam kotak Y, kemudian klik ZPRED lalu pindahkan ke dalam kotak X. Jika kedua variabel tersebut sudah dimasukkan kedalam kotak Y dan kotak X, selanjtnya klik tombol Next untuk kita mengisi plot yang kedua.
Pertama kota tersebut terlihat kosong seperti semula, sekarang pilih ZPRED lalu masukkan kedalam kotak Y, kemudian klik DEPENDNT lalu pindahkan ke dalam kotak X, selanjutnya klik tombol Next untuk kita mengisi plot yang ketiga.
untuk plot yang ketiga pada bagian Standarized Residual Plots cukup centang Normal probability plot saja seperti terlihat pada gambar berikut:
15. Selanjutnya klik Continue dan tekan OK. ANALISIS Bagian Output Descriptive Statistics dan Correlation
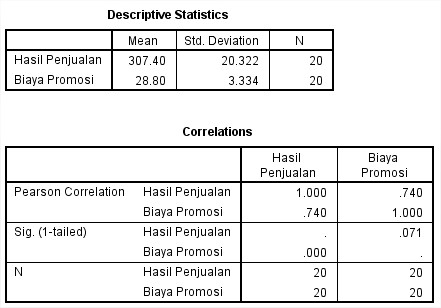
Analisis bagian Descriptive Statistics
Rata-rata hasil penjualan PT ubey motor dari 20 cabang yang ada di Provinsi Aceh adalah Rp. 307.40 juta dengan standar deviasi Rp. 20.332 juta.
Rata-rata biaya promosi PT ubey motor dari 20 cabang adalah Rp. 28.80 juta dengan standar deviasi Rp. 3.334 juta
Analisis bagian Correlations
Besar hubungan antara hasil penjualan dengan biaya promosi dapat diketahui dengan melihat koefesien korelasi adalah 0.740. artinya nilai ini dapat menunjukkan hubungan yang sangat kuat antara hasil penjualan dengan biaya promosi, nilai koefesien korelasi semakin mendekati ke 1 maka semakin sempurna hubungan antara kedua variabel tersebut (arah hubungan ke positif).
Taraf kepercayan yang digunakan yaitu 0.05. diperoleh hasil tingkat signifikan koefesien korelasi sebesar 0.071. karena nilainya lebih besar dari 0.05 maka hubungan hasil penjualan dengan biaya promosi tidak berbeda secara nyata.
Analisis bagian Variables Entered dan Model Summary
Analisis bagian Variabel Entered/Removed Tabel tersebut diperlihatkan bahwa variabel yang kita masukkan yaitu biaya promosi dan tidak terdapat variabel yang dikeluarkan (removed). karena metode yang kita pakai adalah single step
Analisis bagian Model Summary Pada tabel model tersebut dapat diketahui bahwa nilai R sebesar 0.740 atau koefesien korelasi nilai R tersebut dapat dikuadratkan yaitu 0.740 x 0.740 = 0.548. R square (koefesien determinasi) dalam hal ini variasi dari variabel terikat (hasil penjualan) dapat dijelaskan oleh variabel bebas (biaya promosi) yaitu sebesar 54.8%. sedangkan sisanya 45.2% dipengaruhi oleh faktor yang lain. Tingkat besarnya hubungan dari kedua varibabel tersebut dapat dilihat pada tabel berikut:
Dari tabel diatas dapat diketahui bahwa hubungannya kuat antara hasil penjualan dengan biaya promosi.
Standard Error of the Estimate sebesar 15.636 dapat diartikan bahwa hasil penjualan yang dipakai dari variabel terikat sebesar Rp.15.636 juta. sedangkan bila kita lihat pada tabel sebelumnya (tabel descriptive statistics) nilai standar deviasi hasil penjualan diperoleh sebesar Rp. 20.322 juta, nilai ini mendandakan standar error of the estimate lebih besar dari pada yang diperoleh dari model hanya Rp.15.636 juta.
Analisis bagian Anova dan Coefficients
Analisis bagian Anova Dari tabel uji anova diperoleh nilai F tes (F hitung=51.352) dan nilai probabilitas (signifikan) kecil dari 0.05. karena nilai probabilitas kecil dari 0.05 maka model regresi ini dapat digunakan untuk memprediksi hasil penjualan.
Analisis bagian Coeffecients Pada bagian ini kita akan memperoleh persamaan regresi yaitu: Y = 247.727 + 2.072X keterangan: Y = hasil penjualan X = biaya promosi Dari persamaan di atas nilai 247.727 merupakan konstanta, artinya bila tidak ada biaya promosi (x) maka hasil penjualan tetap sebesar 247.727 juta. koefesien regresi 2.072 menandakan setiap ada peningkatan satu satuan (x=biaya promosi) maka Y ada peningkatan satu-satuan tergantung nilai x, begitu juga sebaliknya.
Dalam hal ini uji t sangat dibutuhkan untuk menguji signifikan konstanta dan varibel bebas (biaya promosi). Persamaan regresi yang telah diperoleh sebelumnya akan di uji apakah variabel bebas (biaya promosi) dapat dijadikan sebagai variabel untuk memprediksi hasil penjualan yang akan datang.
Sebelumnya kita buat hipotesis: H0 = koefesien regresi tidak signifikan H1 = koefesien regresi signifikan
Pengujian statistik: jika t hitung < t tabel maka H0 diterima, nilai probabilitas > 0.05 jika t hitung > t tabel maka H1 di tolak, nilai probabilitas < 0.05
dari hasil perhitungan diperoleh nilai t hitung 6.326 dan t tabel 1.73. jadi 6.326 > 1.73. dan nilai signifikan atau probabilitas 0.00. maka berdasarkan pengujian statistik H0 di tolak dan terima H1. Jadi koefesien regresi signifikan atau biaya promosi berpengaruh secara nyata terhadap hasil penjualan.
Kesimpulan: Berdasarkan hasil perhitungan di atas model regresi yang diperoleh sebelumnya dapat dijadikan sebagai alat untuk memprediksi hasil penjualan yang akan datang.
Regresi linier berganda dengan SPSS ΓÇô Analisis regresi linear berganda adalah Salah satu bentuk analisis regresi linier di mana variabel bebasnya lebih dari satu. Analisis regresi adalah analisis yang dapat digunakan untuk mengukur pengaruh suatu variabel bebas terhadap Variabel tidak bebasnya.
Metode analisis ini menjadi salah satu analisis yang banyak digunakan karena alasan mudah dan memiliki kekuatan yang cukup dalam menjelaskan suatu pengaruh suatu variabel bebas ke variabel terikatnya. Ada banyak sekali kondisi yang dapat kita uji dengan analisis regresi linier.
Sediakan data penelitian
Dalam kasus ini, untuk menambah pemahaman mengenai analisis regresi berganda, kita lakukan ujicoba pengujian regresi berganda dengn SPSS, kita ambil salah satu contoh dimana data yang kita masukkan adalah data fiktif.
i
Y
X1
X2
X3
X4
X5
1
521
18308
185
4
80
7,2
2
367
1148
600
0,6
1
8,5
3
443
18068
372
3,7
32
5,7
4
365
7729
142
2,4
45
7,3
5
614
100484
432
29,8
191
7,5
6
385
16728
290
3,3
32
5
7
286
14630
346
3,3
678
6,7
8
397
4008
328
0,7
341
6,2
9
764
38927
354
12,9
240
7,3
10
427
22322
266
6,5
112
5
11
153
3711
320
1,1
173
2,8
12
231
3136
197
1
12
6,1
13
524
50508
266
11,4
206
7,1
14
328
28886
173
5,5
155
5,9
15
240
16996
190
2,8
50
4,6
16
286
13035
239
2,5
30
4,4
17
285
12973
190
3,7
93
7,4
18
569
16309
241
4,2
97
7,1
19
96
5227
189
1,2
40
7,5
20
498
19235
358
4,8
489
5,9
21
481
44487
315
6
768
9
22
468
44213
303
9,3
164
9,2
23
177
23619
228
4,4
55
5,1
24
198
9106
134
2,6
55
8,6
25
458
24917
189
5,1
74
6,6
26
108
3872
196
0,8
6
6,9
27
246
8945
183
1,6
21
2,7
28
291
2373
417
1,2
11
5,5
29
68
7128
233
1,1
124
7,2
30
311
23624
349
7,7
1042
6,6
31
606
5242
284
1,5
13
6,9
32
512
92629
499
18
381
7,2
33
426
28795
231
6,6
136
5,8
34
47
4487
143
0,6
9
4,1
35
265
48799
249
10,8
265
6,4
36
370
14067
195
3,1
46
6,7
37
312
12693
288
2,8
30
6
38
222
62184
229
11,9
265
6,9
39
280
9153
287
1
960
8,5
40
759
14250
224
3,5
116
6,2
41
114
3680
161
0,7
9
3,4
42
419
18063
221
4,9
118
6,6
43
435
65112
237
17
65
6,6
44
186
11340
220
1,7
21
4,9
45
87
4553
185
0,6
61
6,4
46
188
28960
260
6,2
156
5,8
47
303
19201
261
4,9
73
6,3
48
102
7533
118
1,8
75
10,5
49
127
26343
268
4,9
90
5,4
50
251
1641
300
0,5
5
5,1
2. Input Data ke dalam Aplikasi SPSS
tutorial analisis regresi linier berganda dengan SPSS
Masukkan data fiktif ke SPSS (dalam tutorial ini menggunakan SPSS Versi 21)
Pada Menu Bar, pilih Analyze > Regression > Linear
Akan muncul jendela seperti dibawah ini:
Lalu, masukkan variabel Y ke bagian Dependent dan variabel X1, X2, X3, X4, dan X5 ke bagian Independent(s), kemudian klik OK.
tutorial analisis regresi linier berganda dengan SPSS
3. Tentukan Model Summary
4. Lakukan Uji Simultan/UJi F
5. koefisien dan Signifikansi (Persial)/Uji T Penjelasan untuk uji Global (menggunakan tabel anova)
1 Membuat Hipotesis
H0 = Tidak ada pengaruh x1,x2,x3,x4,x5 terhadap y H1 = Ada pengaruh x1,x2,x3,x4,x5 terhadap y
2. Kriteria
JIka sig < alpha (0,05) / F hitung > F tabel maka H0 = di tolak JIka sig > alpha (0,05) / F hitung < F tabel maka H0 = di terima
3. Nilai sig = 0.003
4. Perbandingan
sig (0.003) < alpha (0,05) = H0 ditolak
5. Kesimpulan ada pengaruh x1,x2,x3,x4,x5 terhadap y
Penjelasan untuk uji parsial (menggunakan tabel coefficients)
1 Membuat Hipotesis
H0 = Tidak ada pengaruh x1 terhadap y H1 = Ada pengaruh x1 terhadap y
2. Kriteria
JIka sig < alpha (0,05) / t hitung > t tabel maka H0 = di tolak JIka sig > alpha (0,05) / t hitung < t tabel maka H0 = di terima
3. Nilai sig = 0.596
4. Perbandingan
sig (0.596) > alpha (0,05) = H0 diterima
5. Kesimpulan Tidak ada pengaruh x1 terhadap y
begitu seterusnya x2,x3,x4,x5 terhadap y khusus untuk uji parsial (lihat masing masing hasil dari tabel coefficients)
TETAP MENGGUNAKAN CONTOH DALAM REGRESI LINIER BERGANDA PADA PERTREMUAN KE 11 KITA AKAN MELAKUKAN UJI ASUMSI KLASIK
BERIKUT LANGKAH-LANGKAH UJI ASUMSI KLASIK :
Pengujian Linearitas
Untuk menguji apakah asumsi Linieritas terpenuhi, kita dapat menggunakan plot residual dengan fitted value (predicted value) atau bisa juga dengan plot residual dengan variable independent (John Neter, 1989:118).
Cara menampilkan plot residual vs fitted value di SPSS:
Pilih menu Analyze >> Regression >> Linear
Masukkan variable dependent dan variable-variabel bebas
Klik Save >> centang pada Unstandardized Predicted Value dan Unstandardized Residual >> Continue >> OK
Masukkan variable Unstandardized Residual sebagai Y dan Unstandardized Predicted Value sebagai X >> OK
Maka akan muncul output seperti berikut.
Interpretasi plot:
Berdasarkan plot residual dengan fitted value tersebut, terlihat bahwa tebaran nilai-nilai pada plot membentuk suatu pola acak, sehingga asumsi linieritas terpenuhi.
Pengujian Asumsi Normalitas
Untuk menguji asumsi Normalitas, dapat menggunakan analisis Normal P-P Plot atau dengan uji-uji normalitas seperti uji Liliefors atau Kolmogorov-Smirnov. Namun, pada saat ini kita akan menggunakan uji Kolmogorov-Smirnov untuk menguji normalitas dari residual dari regresi.
Untuk melakukan uji normalitas, pastikan kita telah memiliki variabel Unstandardized Residuals, yang kita dapatkan dari hasil uji linearitas diatas.
Setelah itu, kita dapat melakukan uji Kolmogorov-Smirnov dengan mengklik Analyze >> Nonparametric Test >> Legacy Dialogs >> 1-Sample K-S
Kemudian akan muncul jendela seperti ini, dan masukkan variabel Unstandardized Residuals.
Lalu akan muncul hasil seperti berikut.
Kita perhatikan pada nilai Asymp. Sig. (2-tailed) yang merupakan p-value untuk uji KS ini. P-Value atau Asymp. Sig. (2-tailed) yang dihasilkan sebesar 0,652 yang lebih besar dari alpha=0,05. Hal ini menunjukkan bahwa residual dari regresi telah memenuhi asumsi normalitas.
Pengujian Asumsi Homoskedastisitas
Menurut John Neter (1989:120), untuk mendeteksi terjadinya heteroskedastisitas, dapat menggunakan plot residual dengan fitted values atau Unstandardized Residual VS Unstandardized Predicted Value (yang telah kita lakukan pada uji asumsi Linearitas).
Berdasarkan plot antara unstandardized residual dengan unstandardized predicted value (fitted value) dapat diperhatikan bahwa tebaran titik-titik pada plot tersebut membentuk pola acak. Hal ini mengindikasikan bahwa tidak terjadi heteroskedastisitas pada model regresi yang telah dibuat.
Selain dengan melihat scatter plot, asumsi homoskedastisitas dapat dilihat dengan melakukan uji Park dan uji Rank Spearmen. Pada kesempatan ini kita akan menggunakan uji Park.
lakukan uji Park, kita terlebih dahulu melakukan transformasi logaritma natural terhadap variabel independen. Sedangkan untuk variabel dependen adalah logaritma natural dari kuadrat residual.
Kemudian, lakukan seperti regresi biasa dengan memasukkan logaritma natural dari kuadrat residual sebagai variabel dependen, dan logaritma natural dari masing-masing variabel bebas sebagai variabel independen.
Maka, akan muncul hasil seperti berikut.
Berdasarkan output diatas, dapat kita ketahui bahwa tidak ada variabel yang signifikan sehingga dapat dikatakan bahwa tidak terdapat masalah heteroskedastisitas, sehingga asumsi terpenuhi.
9. Lakukan Pengujian Asumsi Autokolerasi
Untuk menguji asumsi Autokolerasi, akan dilakukan dengan melihat statistik Durbin-Watson. Lakukan regresi seperti biasa, namun pada bagian Statistics, centang bagian Durbin-Watson.
Durbin-Watson di SPSS
Maka akan muncul output seperti berikut.
Berdasarkan output tersebut, diketahui nilai statistic hitung Durbin -Watson yaitu D = 2.173.
Dari TABLE A.6 Durbin ΓÇô Watson Test Bounds (John Neter, 1989:642), untuk p-1= 5 dan n=50 , maka diperoleh nilai:
dL=1.34,
dU=1.77,
4−dU=2.23,
4−dL=2.66,
Nilai statistic hitung D = 2.173 >dU
Karena nilai DW lebih besar dari du , maka dapat kita ketahui bahwa tidak terdapat masalah autokorelasi.
Pengujian Asumsi Multikolinearitas
Untuk menguji asumsi multikolinearitas, dapat dilakukan dengan melihat nilai korelasi antar variabel independen.
Klik Analyze >> Correlation >> Bivariate lalu masukkan seluruh variabel independen.
Berdasarkan output diatas dapat kita lihat bahwa korelasi antara variabel X1 dan X3 sebesar 0,959 (korelasi yang sangat kuat) sehingga dapat kita simpulkan bahwa terdapat multikolinearitas pada model regresi tersebut.
Chi-Square atau uji keselarasan merupakan salah satu uji yang paling sering digunakan dalam menganalisis data berskala nominal, bertujuan untuk menguji signifikan pada suatu sampel, uji homogenitas, uji independent dan uji goodness of fit tes. Uji goodness of fit tes hanya saja untuk membandingkan dua distribusi data, yaitu apakah sebuah distribusi data dari sampel mengikuti sebuah distribusi teoritis (frekuensi harapan) dan dibandingkan dengan dengan kenyataan yang ada (observasi). Kali ini kita akan menggunakan chi-square untuk menguji perbedaan antara distribusi frekuensi harapan dengan observasi.
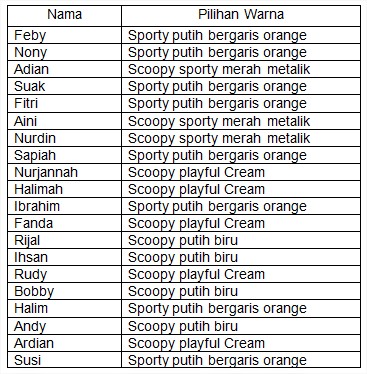
Contoh:
Manajer pemasaran Dealer menyediakan 4 warna honda scoopy yang hendak dijual kepada konsumen, selama ini manajer pemasaran menganggap bahwa tidak semua konsumen yang hendak membeli mereka sama-sama menyukai ke empat warna honda Scoopy berupa Scoopy sporty merah metalik, Sporty putih bergaris orange, Scoopy playful Cream, Scoopy putih biru. untuk itu manajer pemasaran ingin mengetahui apakah anggapan tersebut benar bahwa semua konsumen menyukai ke empat warna honda scoopy. untuk membuktikan anggapannya manajer menggunakan 20 orang responden. Berikut data pilihan dari 20 responden.
Hipotesis:
H0: tidak semua konsumen menyukai sama-sama ke empat warna honda Scoopy yang ada
H1: semua konsumen menyukai sama-sama ke empat warna honda Scoopy yang ada
Pengujian Statistik: taraf signifikan (95% atau 0.05)
jika chi-square hitung < chi-square tabel atau nilai probabilitas > 0.05, maka H0 diterima
jika chi-square hitung > chi-square tabel atau nilai probabilitas < 0.05, maka H0 ditolak
Langkah-langkah menggunakan SPSS
1. buka aplikasi SPSS
2. Lalu klik variabel view (ada di pojok bawah sebelah kiri) untuk mengisi variabel
3. Lalu isi variabel view (kolom name ketik Warna, Type isi Numeric, Decimals ketik 0, Label ketik Warna Honda Scoopy, Value lihat posisi tanda panah seperti gambar di bawah lalu klik kemudian pada kolom value ketik 1 lalu pada kolom Label ketik Sporty putih bergaris orange lalu klik Add,begitu juga untuk yang ke 2=Scoopy sporty merah metalik, 3=Scoopy playful Cream, 4=Scoopy putih biru, Measure ketik Nominal) sedangkan kolom lain abaikan saja. atau caranya dapat dilihat seperti gambar berikut:
4. Selanjutnya kita isi data pilihan warna yang telah dipilih oleh responden berupa skala nominal dengan cara: klik data view (ada di pojok bawah sebelah kiri), lalu ketik seperti gambar dibawah. Jika data sudah selesai di isi selanjutnya pada menu toolbar paling atas pilih Analyze---> Nonparametric Tests---> Legacy Dialogs---> klik Chi-square. atau caranya seperti gambar berikut:
5. Jika sudah mengikuti sesuai dengan perintah di atas maka muncul halaman Chi-square test, selanjutnya kita akan mengisi kotak Chi-square test. dengan cara pindahkan warna honda scoopy (warna) yang ada pada kotak sebelah kiri ke dalam kotak sebelah kanan (Test Variable List) seperti pada gambar
6. Selanjutnya klik OK
Analisis
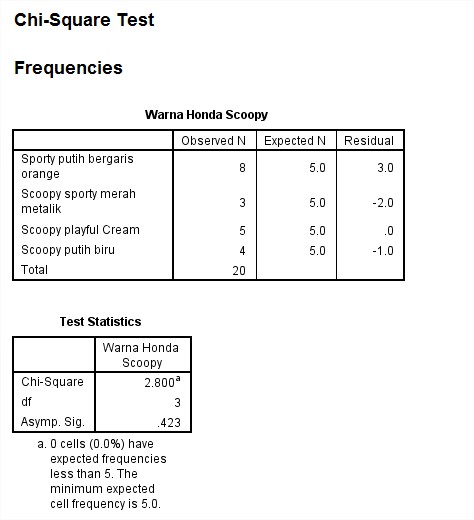
Dari hasil output dapat kita ketahui bahwa pada bagian Warna Honda Scoopy kolom Observed N masing-masing warna pilihannya berbeda, artinya warna Sporty putih bergaris orange 8 orang, warna Scoopy sporty merah metalik 3 orang, warna Scoopy playful Cream 5 orang, warna Scoopy putih biru 4 orang. jadi jumlah keseluruhan pemilih ada 20 orang. Pada kolom Expected N dapat dijelaskan karena pilihan responden tidak semua warna sama, maka masing-masing warna yang dipilih berbeda, jadi anggapan manajer dalam hal ini sudah mendekati kebenarannya (nilai 5 diperoleh dari 20 responden dibagi 4 warna). sedangkan Residual tersebut artinya sisanya dari masing-masing warna (nilai residual+expected atau nilai ecpected-residual maka akan menghasilkan nilai observed N setiap warna).
Selanjutnya kita akan menganalisis bagian hasil Test Statistics, dari hasil tersebut diperoleh nilai Chi-square hitung 2.800. nilai tersebut kita bandingkan dengan nilai chi-square tabel, nilai schi-square tabel di dapat 7.81. dan nilai Asymp. sig (probabilitas) diperoleh 0.423.
Tinjau pengujian statistik:
Karena chi-square hitung < chi-square tabel yaitu: 2.800 < 7.815 dan nilai sig >0.05 yaitu 0.423. maka dalam hal ini H0 diterima.
Kesimpulan:
Berdasarkan pengujian statistik diatas maka dapat di ambil kesimpulan bahwa tidak semua konsumen menyukai sama-sama ke empat warna honda Scoopy yang ada, maka dalam hal ini pihak manajer pemasaran sudah benar anggapannnya.
 Tentu Anda sering mendengar program statistika satu ini, di perkuliahan atau pun di beberapa perusahaan besar pun menggunakan software statistika ini. SPSS singkatan dari Statistical Package for the Social Software. Pertama kali dirilis pada tahun 1968 yang dikembangkan oleh Norman H. Nie dan C. Hadlai Hull.SPSS pertama kalo muncul dengan versi PC dengan nama SPSS/PC+ (versi DOS). Setelah mulai populernya sistem WINDOWS maka SPSS berkembang mulai dari versi 6.0 hingga sekarang. SPSS pada awalnya dibuat untuk keperluan pengolahan data statistik untuk ilmu-ilmu sosial (sesuai dengan singkatan dari SPSS itu sendiri).SPSS pada tanggal 28 Juli 2009 disebut sebagai PASW (Predictive Analytics SoftWare), karena perusahaan ini telah dibeli oleh perusahaan IBM dengan harga US$ 1,2 milyar. Dan pada Januari 2010 menjadi SPSS : Sebuah Perusahaan IBMΓÇ¥, dan menjadi nama IBM SPSS yang sepenuhnya diintegrasikan ke dalam IBM Corporation dan merupakan salah satu merk dibawah IBM Software Group Portofolio Bisnis Analytics bersama dengan IBM Cognos.2. MINITAB
Tentu Anda sering mendengar program statistika satu ini, di perkuliahan atau pun di beberapa perusahaan besar pun menggunakan software statistika ini. SPSS singkatan dari Statistical Package for the Social Software. Pertama kali dirilis pada tahun 1968 yang dikembangkan oleh Norman H. Nie dan C. Hadlai Hull.SPSS pertama kalo muncul dengan versi PC dengan nama SPSS/PC+ (versi DOS). Setelah mulai populernya sistem WINDOWS maka SPSS berkembang mulai dari versi 6.0 hingga sekarang. SPSS pada awalnya dibuat untuk keperluan pengolahan data statistik untuk ilmu-ilmu sosial (sesuai dengan singkatan dari SPSS itu sendiri).SPSS pada tanggal 28 Juli 2009 disebut sebagai PASW (Predictive Analytics SoftWare), karena perusahaan ini telah dibeli oleh perusahaan IBM dengan harga US$ 1,2 milyar. Dan pada Januari 2010 menjadi SPSS : Sebuah Perusahaan IBMΓÇ¥, dan menjadi nama IBM SPSS yang sepenuhnya diintegrasikan ke dalam IBM Corporation dan merupakan salah satu merk dibawah IBM Software Group Portofolio Bisnis Analytics bersama dengan IBM Cognos.2. MINITAB Software statistika berikutnya adalah MINITAB yaitu program komputer yang dirancang untuk melakukan pengolahan statistik. Minitab menggabungkan kemudahan penggunaan layaknya Microsoft Excel dengan kemampuannya melakukan analisis statistik yang kompleks.Minitab dikembangkan di Pennsylvania State University oleh periset Barbara F. Ryan, Thomas A. Ryan, Jr., dan Brian L. Joiner pada tahun 1972. Minitab didistribusikan oleh Minitab Inc, sebuah perusahaan swasta yang bermarkas di State College, Pensylvania dengan kantor cabang Coventry,Inggris (Minitab Ltd) Paris, Perancis (Minitab SARL) dan Sydney, Australia (Minitab Pty.).Minitab seringkali digunakan dalam perusahaan industri sebagai implementasi Six Sigma ΓÇô TQM, CMMIserta metode perbaikan proses yang berbasis statistik lainnya dikenal dengan Design of Experiment (DOE). Minitab Inc, juga membuat perangkat lunak sebagai pelengkap Minitab 16, Quality Trainer danQuality Companion 3.
Software statistika berikutnya adalah MINITAB yaitu program komputer yang dirancang untuk melakukan pengolahan statistik. Minitab menggabungkan kemudahan penggunaan layaknya Microsoft Excel dengan kemampuannya melakukan analisis statistik yang kompleks.Minitab dikembangkan di Pennsylvania State University oleh periset Barbara F. Ryan, Thomas A. Ryan, Jr., dan Brian L. Joiner pada tahun 1972. Minitab didistribusikan oleh Minitab Inc, sebuah perusahaan swasta yang bermarkas di State College, Pensylvania dengan kantor cabang Coventry,Inggris (Minitab Ltd) Paris, Perancis (Minitab SARL) dan Sydney, Australia (Minitab Pty.).Minitab seringkali digunakan dalam perusahaan industri sebagai implementasi Six Sigma ΓÇô TQM, CMMIserta metode perbaikan proses yang berbasis statistik lainnya dikenal dengan Design of Experiment (DOE). Minitab Inc, juga membuat perangkat lunak sebagai pelengkap Minitab 16, Quality Trainer danQuality Companion 3.
 LISREL adalah software statistik yang ketiga dan paling sering digunakan dalam dunia pendidikan. Singkatan dari LISREL adalahLinear Structural Relationship. Pada awalnya dikembangkan olehKarl Joreskog (1973) yang merupakan sebuah nama model persamaan struktural. Dan selanjutnya dikembangkan software komputer yang mendukungnya oleh Joreskog dan Sorbom. Pertama kali software yang tersedia untuk umum adalah LISREL versi 3 tahun 1975. Dan sekarang sudah mencapai LISREL 8.8.
LISREL adalah software statistik yang ketiga dan paling sering digunakan dalam dunia pendidikan. Singkatan dari LISREL adalahLinear Structural Relationship. Pada awalnya dikembangkan olehKarl Joreskog (1973) yang merupakan sebuah nama model persamaan struktural. Dan selanjutnya dikembangkan software komputer yang mendukungnya oleh Joreskog dan Sorbom. Pertama kali software yang tersedia untuk umum adalah LISREL versi 3 tahun 1975. Dan sekarang sudah mencapai LISREL 8.8.
 EVIEWS singkatan dari Economic Views merupakan perangkat lunak (software) yang banyak digunakan untuk kepentingan analisis data ekonomi dan keuangan. Pada awalnya dikembangkan dan didistribusikan oleh Quantitative Micro Software(QMS). EVIEWS menyajikan perangkat analisis data, regresi dan peramalan (regression and forecasting). EVIEWS dapat memanipulasi data time series. EVIEWS memanfaatkan lingkungan WINDOWS user-friendly dan kegunaan lainnya antara lain analisis data dan evaluasinya, analisis keuangan, peramalan ekonomi makro, simulasi, peramalan penjualan dan analisis biaya.
EVIEWS singkatan dari Economic Views merupakan perangkat lunak (software) yang banyak digunakan untuk kepentingan analisis data ekonomi dan keuangan. Pada awalnya dikembangkan dan didistribusikan oleh Quantitative Micro Software(QMS). EVIEWS menyajikan perangkat analisis data, regresi dan peramalan (regression and forecasting). EVIEWS dapat memanipulasi data time series. EVIEWS memanfaatkan lingkungan WINDOWS user-friendly dan kegunaan lainnya antara lain analisis data dan evaluasinya, analisis keuangan, peramalan ekonomi makro, simulasi, peramalan penjualan dan analisis biaya.
 STATA adalah singkatan dari Statistika dan Data yaitu program komputer yang digunakan untuk analisa statistika dan dibuat olehStataCorp tahun 1985. Dirancang untuk keperluan ekonomi, sosiologi dan epidemiologi dengan berbagai fitur manajemen data, analisis statistika, grafik, simulasi dan pemograman.
STATA adalah singkatan dari Statistika dan Data yaitu program komputer yang digunakan untuk analisa statistika dan dibuat olehStataCorp tahun 1985. Dirancang untuk keperluan ekonomi, sosiologi dan epidemiologi dengan berbagai fitur manajemen data, analisis statistika, grafik, simulasi dan pemograman.




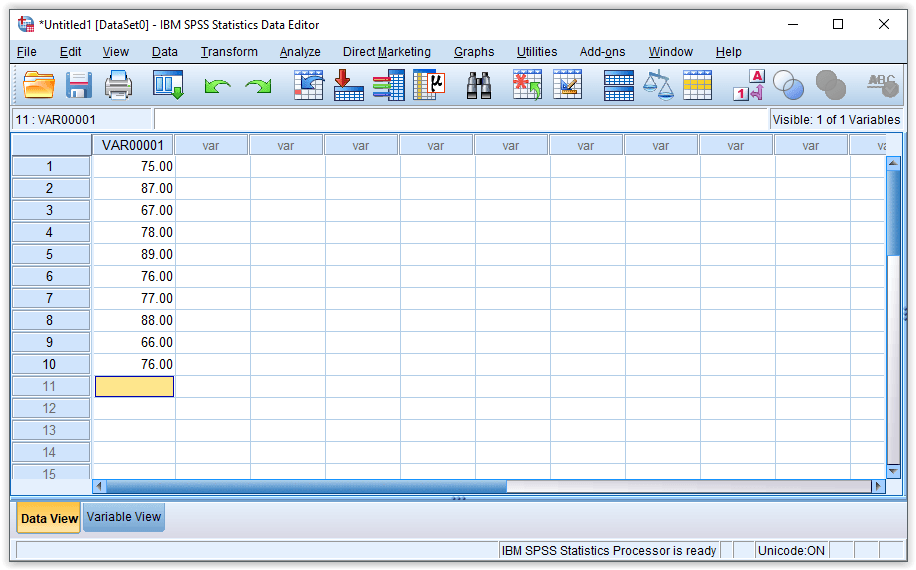
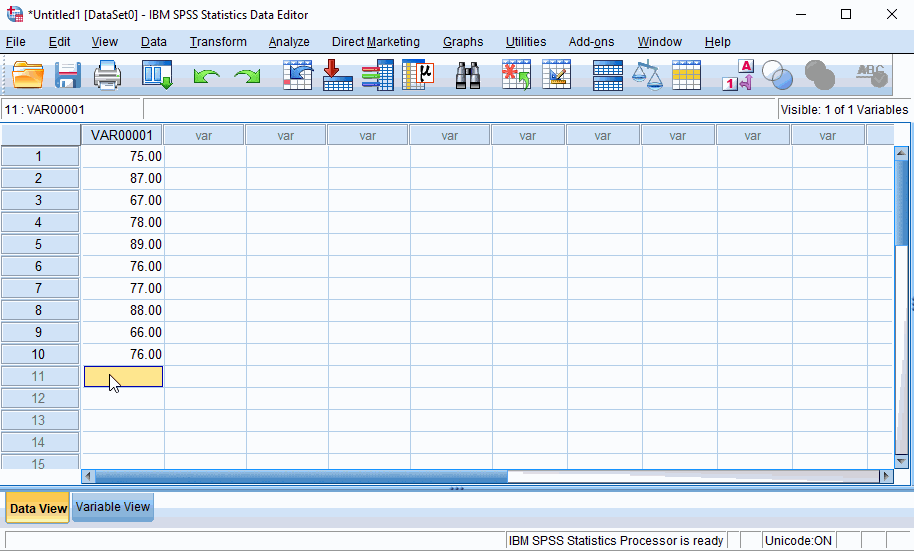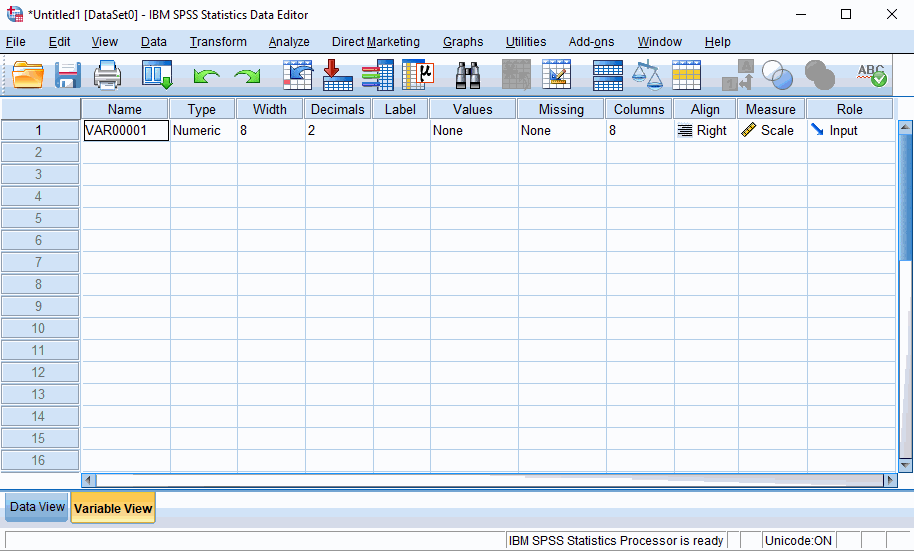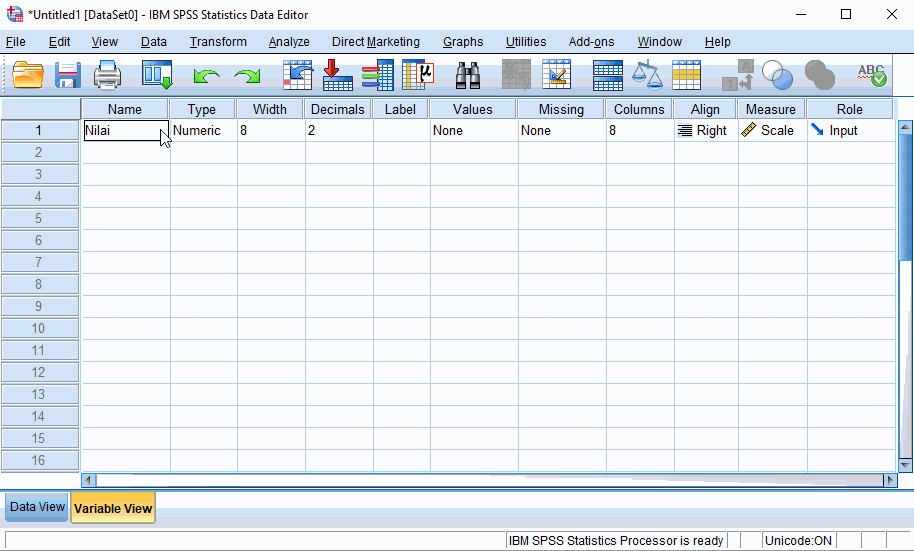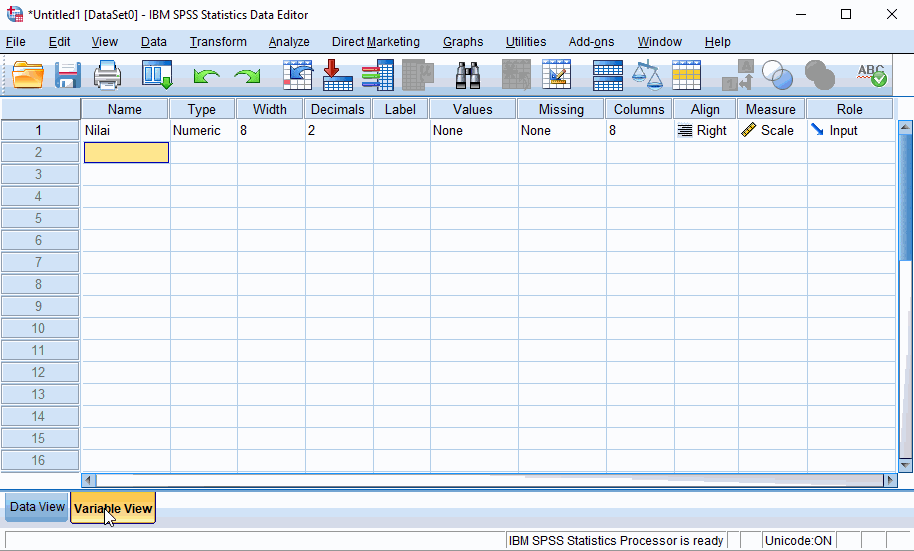
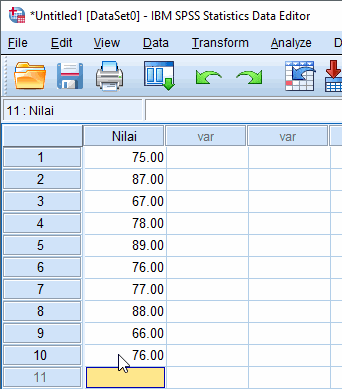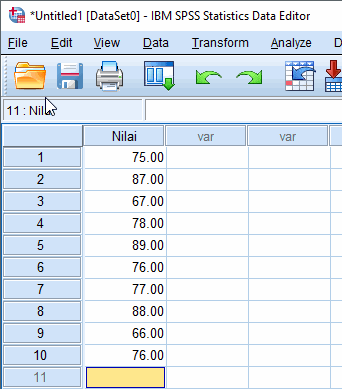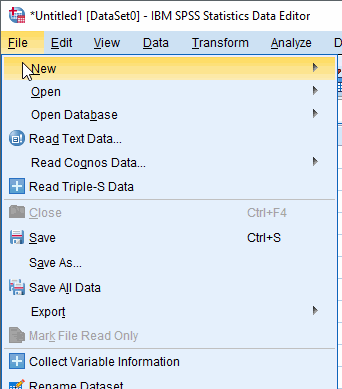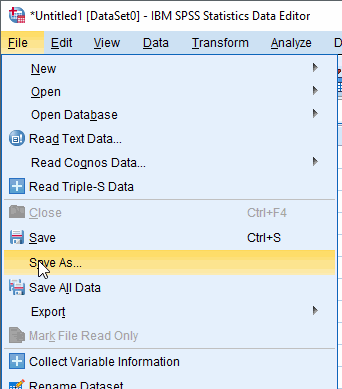
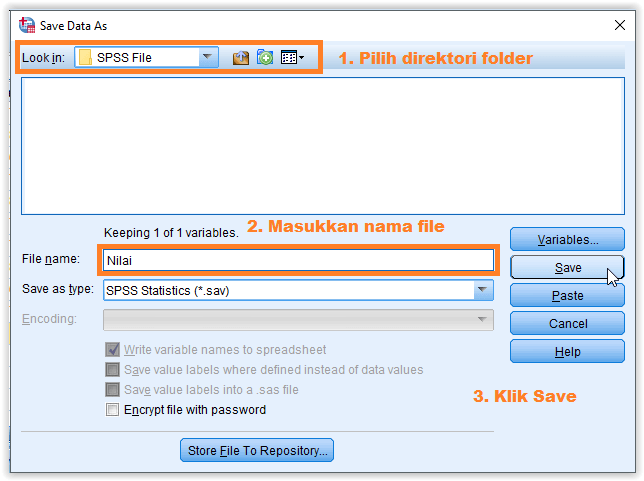
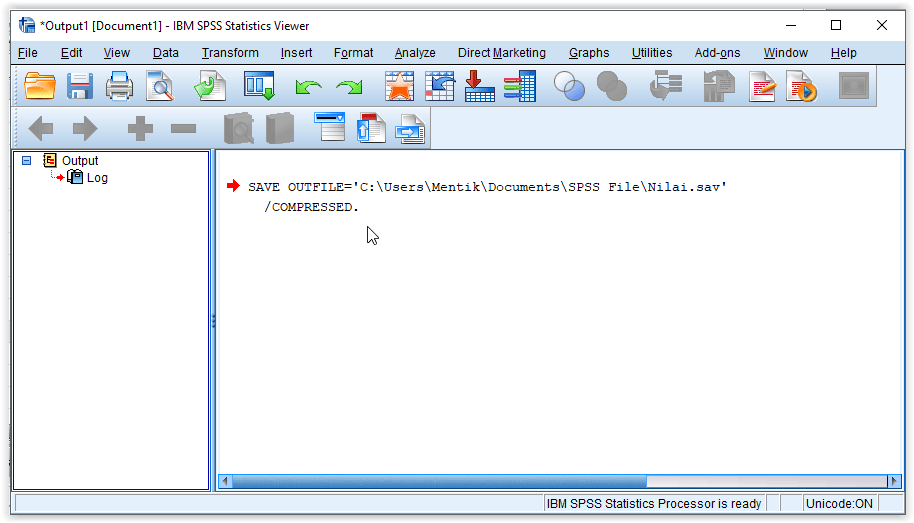
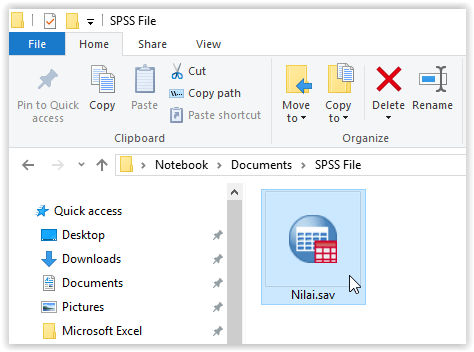
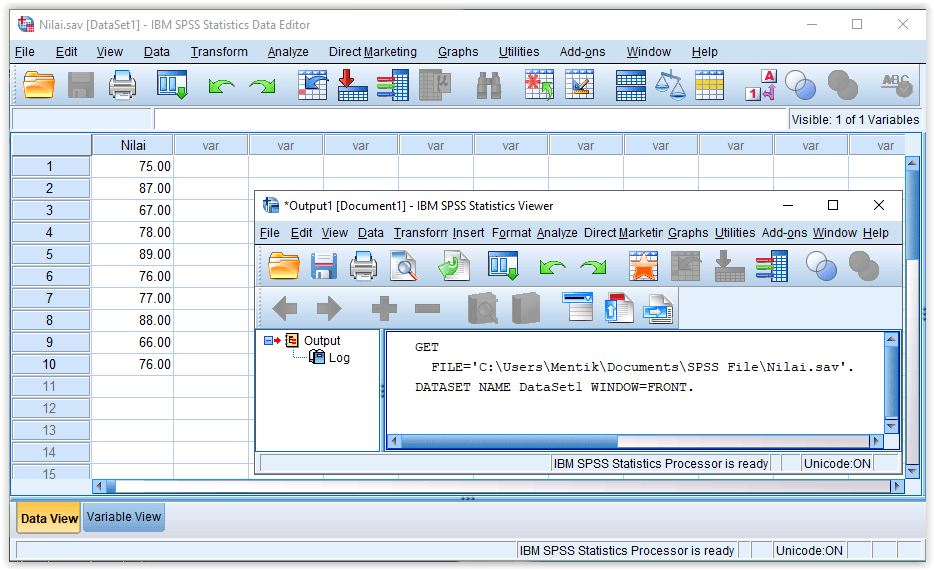
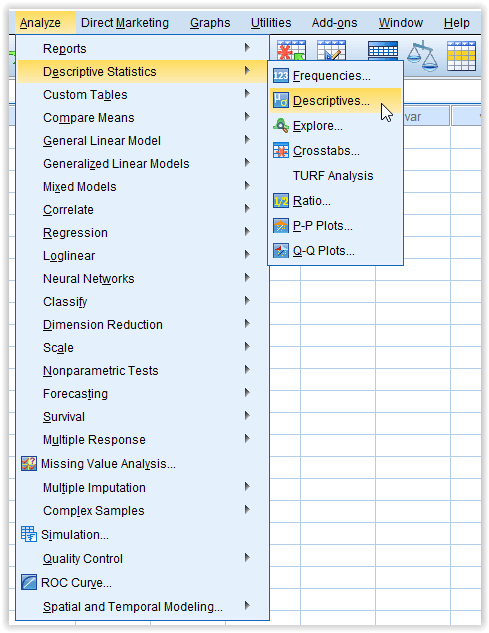
 , sehingga nama variabel terlihat di kolom sebelah kanan Variable(s). Seperti berikut,
, sehingga nama variabel terlihat di kolom sebelah kanan Variable(s). Seperti berikut,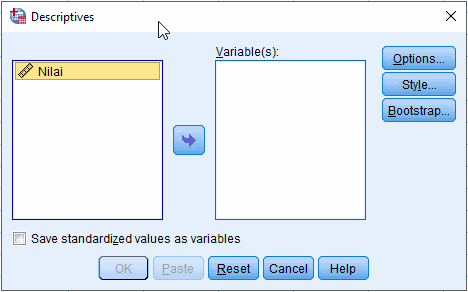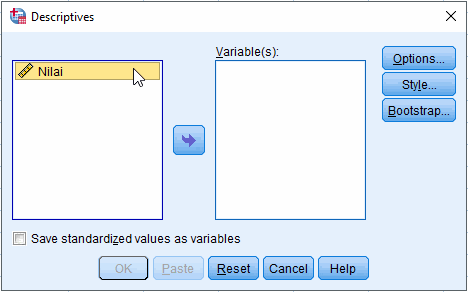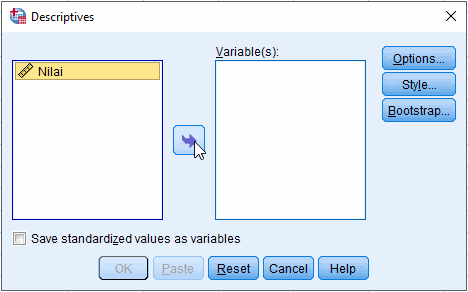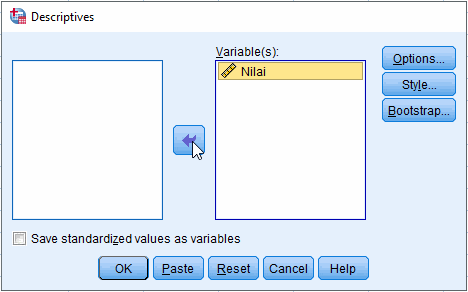
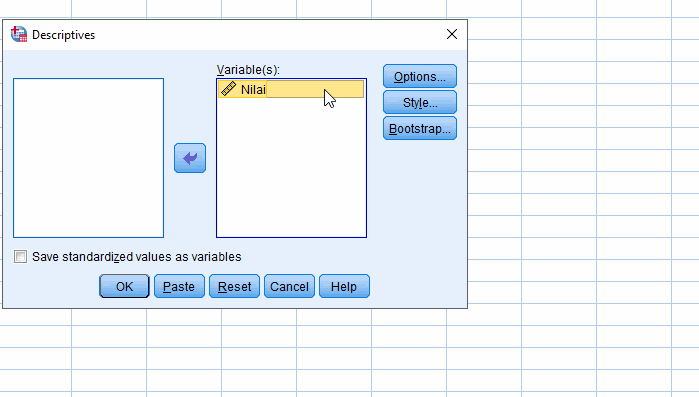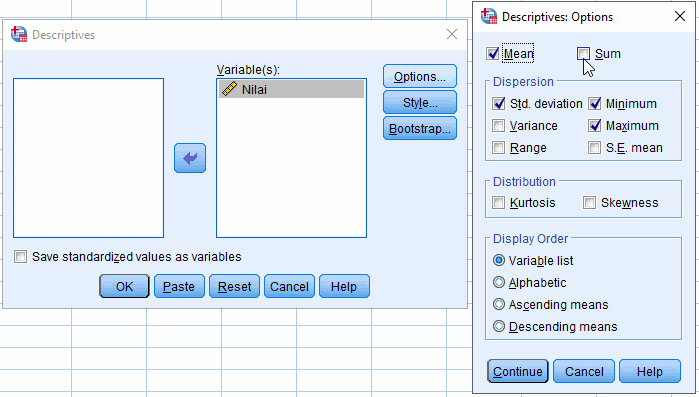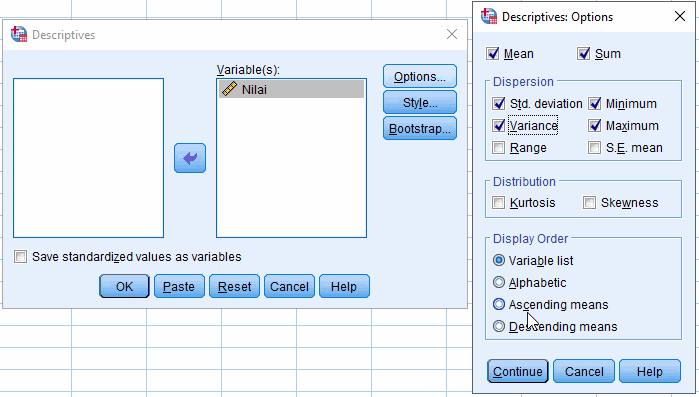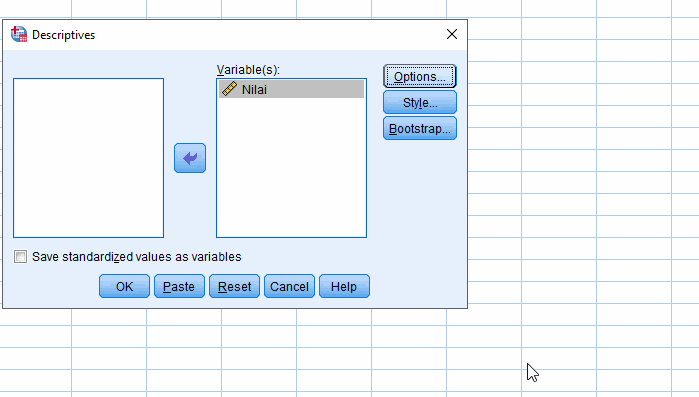
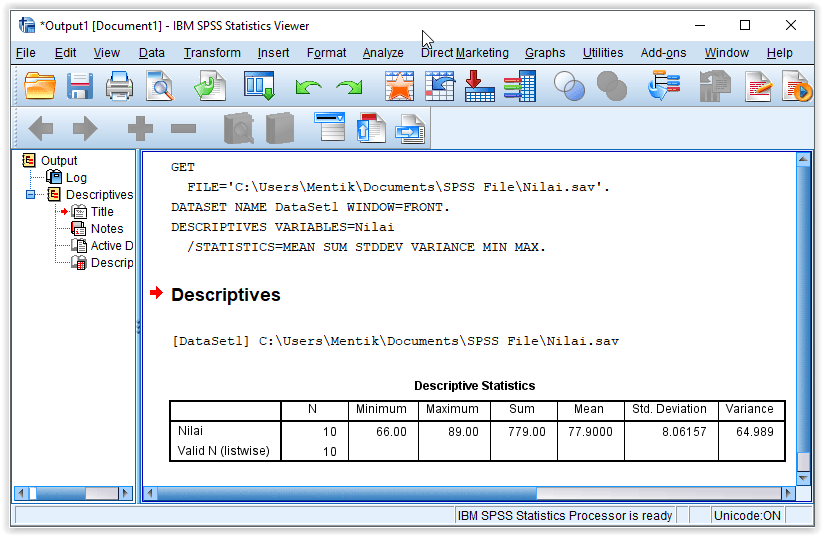
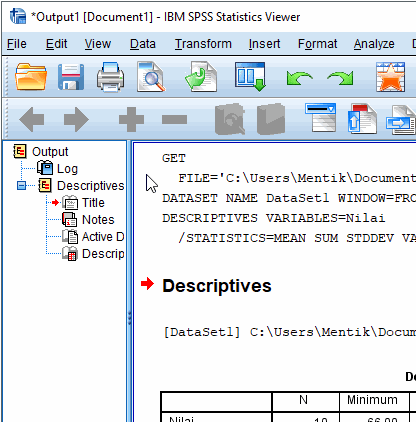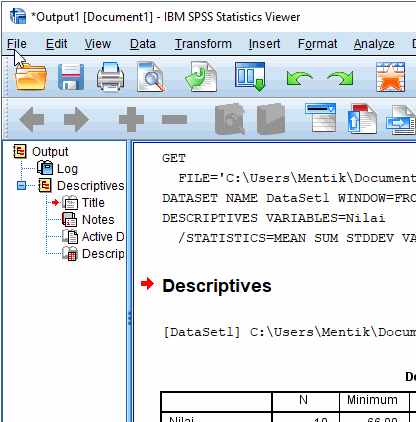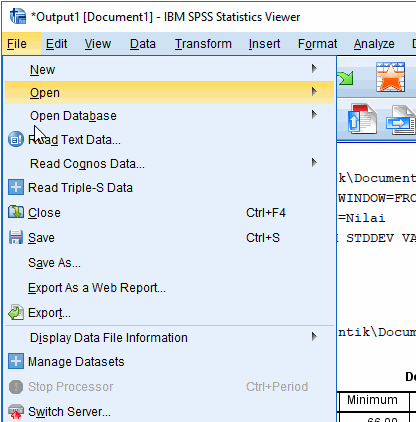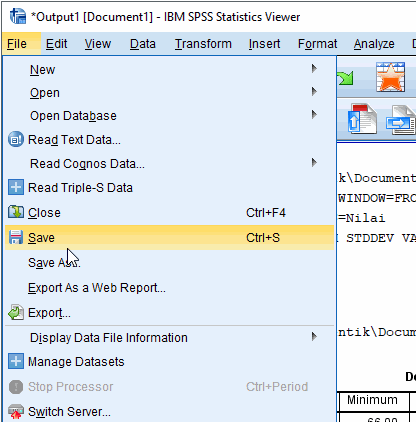
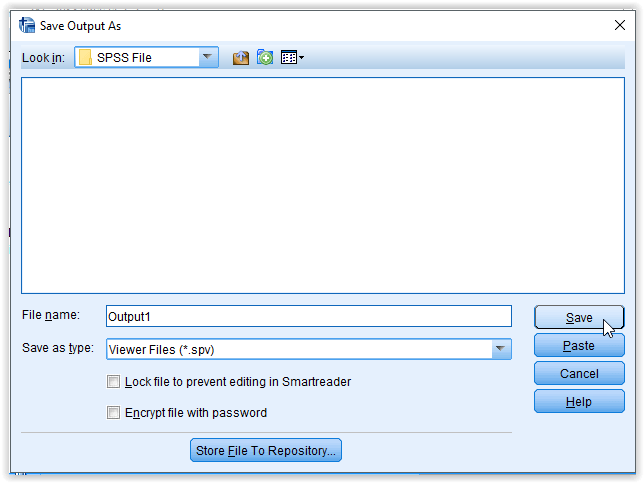
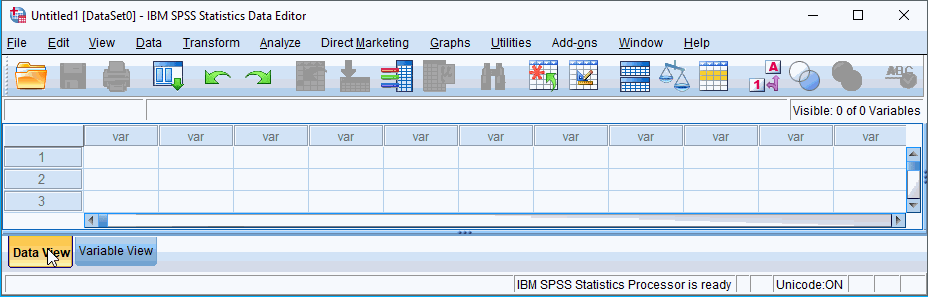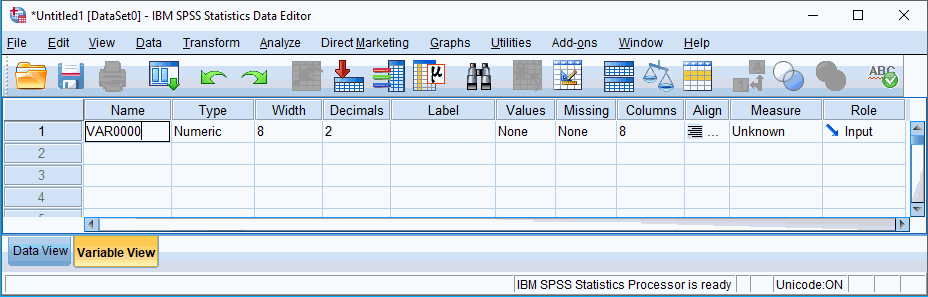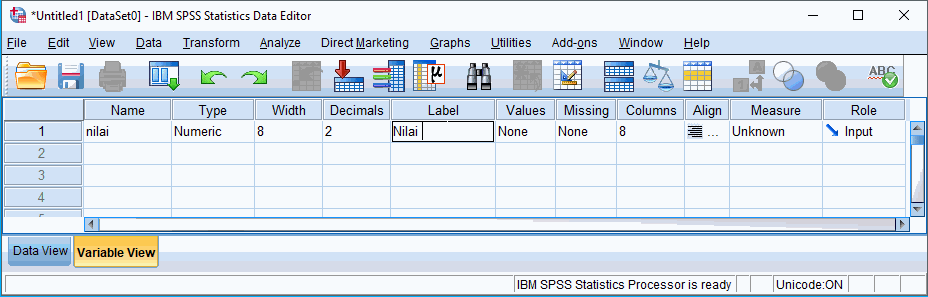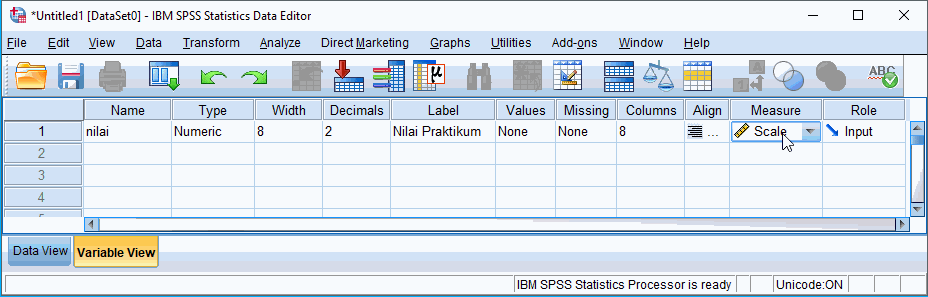
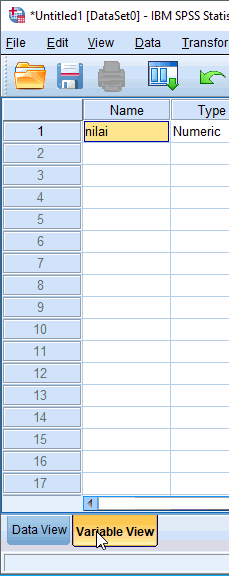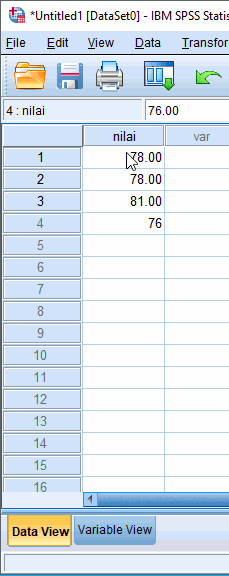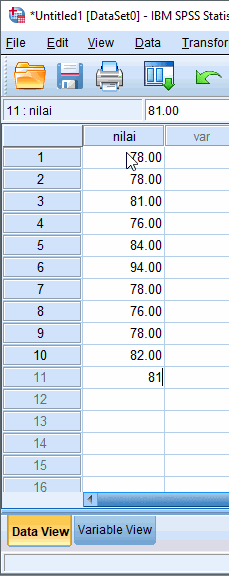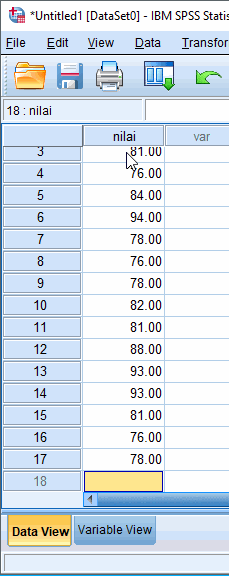
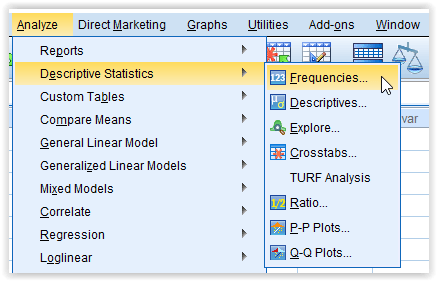
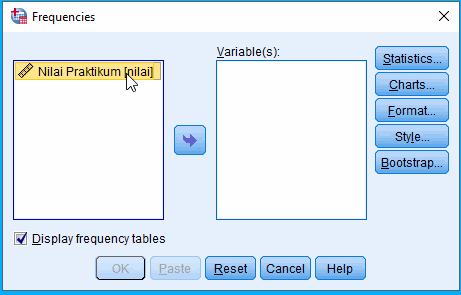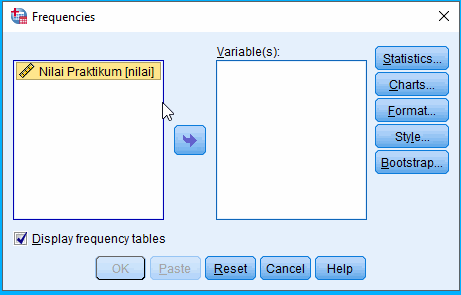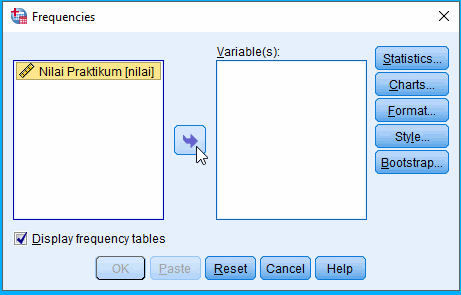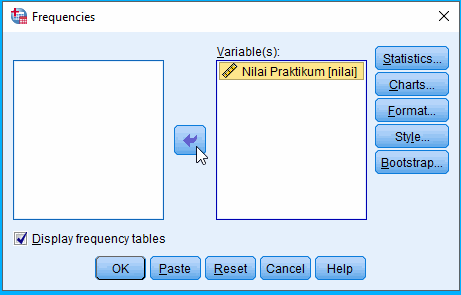
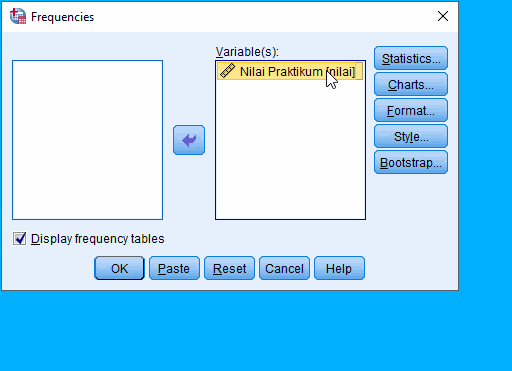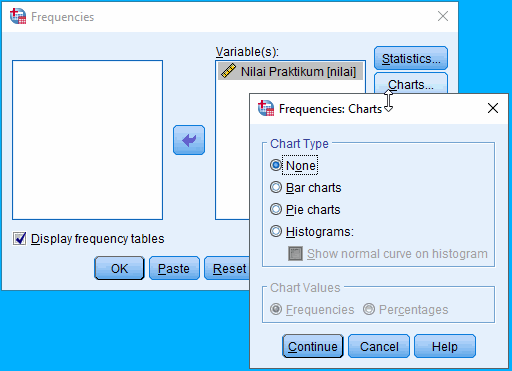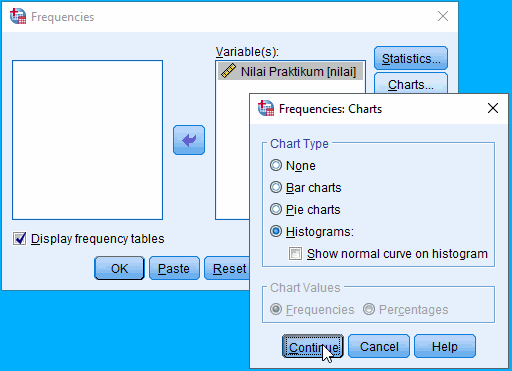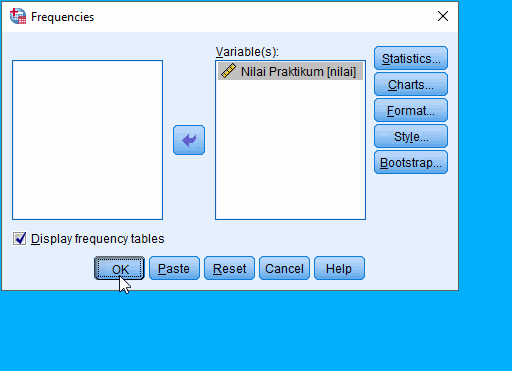
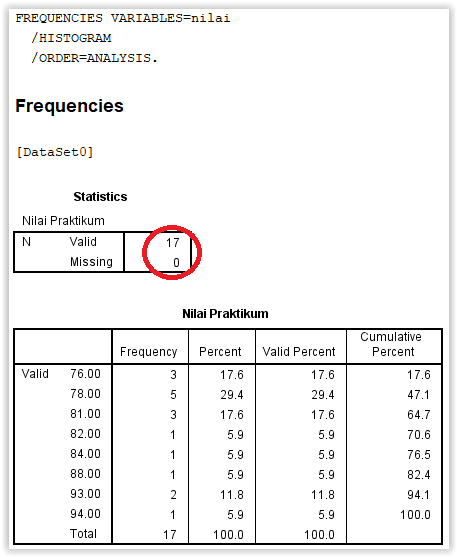
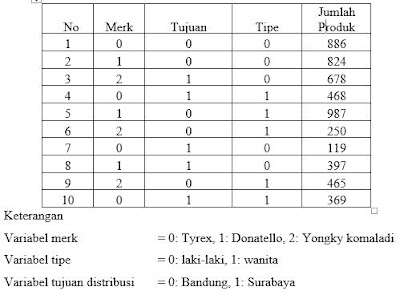

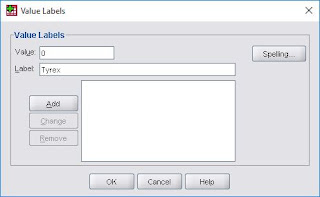



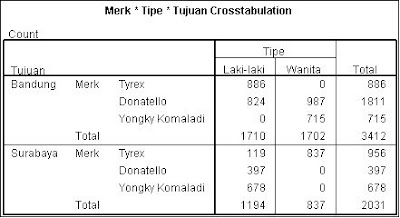


























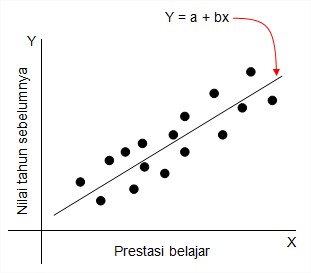 Dalam hal ini kita dapat menyatakan secara matematik dengan sebuah persamaan garis lurus yang disebut garis regresi linear. Sebuah garis lurus dapat ditulis dalam bentuk:Y = a + bxDari persamaan garis di atas dalam hal ini Y digunakan untuk membedakan antara nilai ramalan yang didapat dari garis regresi dan nilai pengamatan Y yang sesungguhnya untuk nilai x tertentu, sedangkan a dapat dinyatakan sebagai intercept atau perpotongan dengan sumbu tegak, dan b itu kemiringan garis yang dikalikan dengan nilai x lalu ditambahkan dengan nilai a yang bertujuan untuk meramalkan nilai Y yang berpadanan pada suatu nilai x tertentu.
Dalam hal ini kita dapat menyatakan secara matematik dengan sebuah persamaan garis lurus yang disebut garis regresi linear. Sebuah garis lurus dapat ditulis dalam bentuk:Y = a + bxDari persamaan garis di atas dalam hal ini Y digunakan untuk membedakan antara nilai ramalan yang didapat dari garis regresi dan nilai pengamatan Y yang sesungguhnya untuk nilai x tertentu, sedangkan a dapat dinyatakan sebagai intercept atau perpotongan dengan sumbu tegak, dan b itu kemiringan garis yang dikalikan dengan nilai x lalu ditambahkan dengan nilai a yang bertujuan untuk meramalkan nilai Y yang berpadanan pada suatu nilai x tertentu.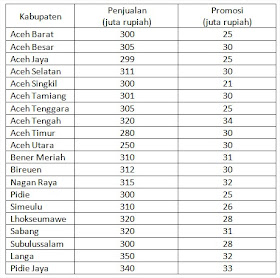
 4. Selanjutnya pilih menu Analyze --- > Regression ---> Linear. bila sudah maka terlihat seperti gambar berikut:
4. Selanjutnya pilih menu Analyze --- > Regression ---> Linear. bila sudah maka terlihat seperti gambar berikut: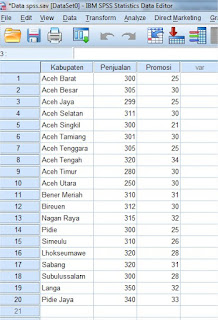 5. Pindahkan variabel Hasil Penjualan [Penjualan] ke dalam kotak Dependent
5. Pindahkan variabel Hasil Penjualan [Penjualan] ke dalam kotak Dependent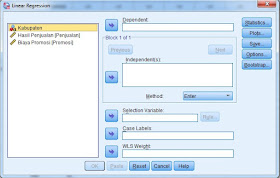
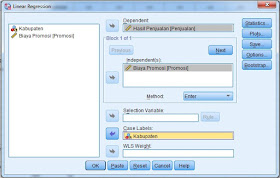 10. Dari gambar di atas dapat kita ketahui bahwa pada kotak Stepping Method Criteria kita menggunakan uji F dengan taraf kepercayaan 5% atau nilai probabilitas 0.05 yang terdapat pada kotak Entry. Biarkan secara default yaitu include constant in equation. Pada kotak Missing Values biarkan secara default yaitu Exclude cases listwise kegunaannya untuk penanganan missing value atau tidak ada data yang hilang. Selanjtnya klik Continue maka akan kembali ke gambar seperti pada langkah 8
10. Dari gambar di atas dapat kita ketahui bahwa pada kotak Stepping Method Criteria kita menggunakan uji F dengan taraf kepercayaan 5% atau nilai probabilitas 0.05 yang terdapat pada kotak Entry. Biarkan secara default yaitu include constant in equation. Pada kotak Missing Values biarkan secara default yaitu Exclude cases listwise kegunaannya untuk penanganan missing value atau tidak ada data yang hilang. Selanjtnya klik Continue maka akan kembali ke gambar seperti pada langkah 8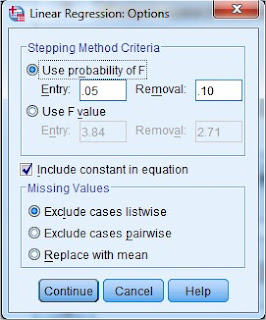
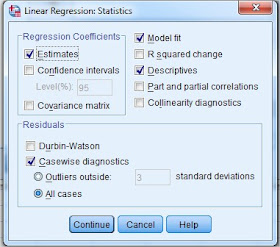
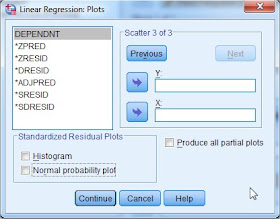 14. Dari gambar di atas, merupakan tampilan plot dapat digunakan untuk menguji asumsi-asumsi pada regresi, seperti uji normalitas, uji linieritas, dan uji kesamaan varians dari variabel.
14. Dari gambar di atas, merupakan tampilan plot dapat digunakan untuk menguji asumsi-asumsi pada regresi, seperti uji normalitas, uji linieritas, dan uji kesamaan varians dari variabel.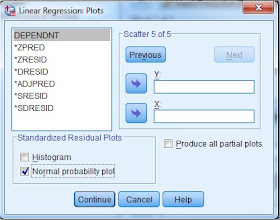
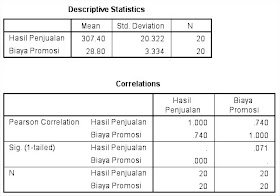 Analisis bagian Descriptive Statistics
Analisis bagian Descriptive Statistics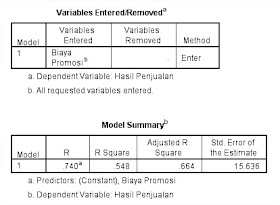





















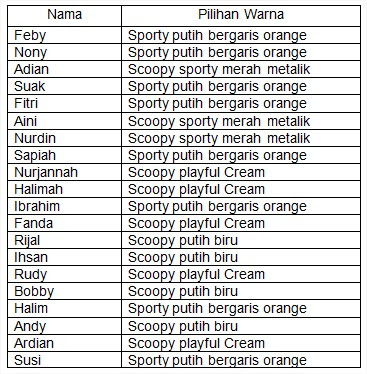 Hipotesis:H0: tidak semua konsumen menyukai sama-sama ke empat warna honda Scoopy yang adaH1: semua konsumen menyukai sama-sama ke empat warna honda Scoopy yang adaPengujian Statistik: taraf signifikan (95% atau 0.05)jika chi-square hitung < chi-square tabel atau nilai probabilitas > 0.05, maka H0 diterimajika chi-square hitung > chi-square tabel atau nilai probabilitas < 0.05, maka H0 ditolakLangkah-langkah menggunakan SPSS1. buka aplikasi SPSS2. Lalu klik variabel view (ada di pojok bawah sebelah kiri) untuk mengisi variabel3. Lalu isi variabel view (kolom name ketik Warna, Type isi Numeric, Decimals ketik 0, Label ketik Warna Honda Scoopy, Value lihat posisi tanda panah seperti gambar di bawah lalu klik kemudian pada kolom value ketik 1 lalu pada kolom Label ketik Sporty putih bergaris orange lalu klik Add, begitu juga untuk yang ke 2=Scoopy sporty merah metalik, 3=Scoopy playful Cream, 4=Scoopy putih biru, Measure ketik Nominal) sedangkan kolom lain abaikan saja. atau caranya dapat dilihat seperti gambar berikut:
Hipotesis:H0: tidak semua konsumen menyukai sama-sama ke empat warna honda Scoopy yang adaH1: semua konsumen menyukai sama-sama ke empat warna honda Scoopy yang adaPengujian Statistik: taraf signifikan (95% atau 0.05)jika chi-square hitung < chi-square tabel atau nilai probabilitas > 0.05, maka H0 diterimajika chi-square hitung > chi-square tabel atau nilai probabilitas < 0.05, maka H0 ditolakLangkah-langkah menggunakan SPSS1. buka aplikasi SPSS2. Lalu klik variabel view (ada di pojok bawah sebelah kiri) untuk mengisi variabel3. Lalu isi variabel view (kolom name ketik Warna, Type isi Numeric, Decimals ketik 0, Label ketik Warna Honda Scoopy, Value lihat posisi tanda panah seperti gambar di bawah lalu klik kemudian pada kolom value ketik 1 lalu pada kolom Label ketik Sporty putih bergaris orange lalu klik Add, begitu juga untuk yang ke 2=Scoopy sporty merah metalik, 3=Scoopy playful Cream, 4=Scoopy putih biru, Measure ketik Nominal) sedangkan kolom lain abaikan saja. atau caranya dapat dilihat seperti gambar berikut: 4. Selanjutnya kita isi data pilihan warna yang telah dipilih oleh responden berupa skala nominal dengan cara: klik data view (ada di pojok bawah sebelah kiri), lalu ketik seperti gambar dibawah. Jika data sudah selesai di isi selanjutnya pada menu toolbar paling atas pilih Analyze---> Nonparametric Tests---> Legacy Dialogs---> klik Chi-square. atau caranya seperti gambar berikut:
4. Selanjutnya kita isi data pilihan warna yang telah dipilih oleh responden berupa skala nominal dengan cara: klik data view (ada di pojok bawah sebelah kiri), lalu ketik seperti gambar dibawah. Jika data sudah selesai di isi selanjutnya pada menu toolbar paling atas pilih Analyze---> Nonparametric Tests---> Legacy Dialogs---> klik Chi-square. atau caranya seperti gambar berikut: 5. Jika sudah mengikuti sesuai dengan perintah di atas maka muncul halaman Chi-square test, selanjutnya kita akan mengisi kotak Chi-square test. dengan cara pindahkan warna honda scoopy (warna) yang ada pada kotak sebelah kiri ke dalam kotak sebelah kanan (Test Variable List) seperti pada gambar
5. Jika sudah mengikuti sesuai dengan perintah di atas maka muncul halaman Chi-square test, selanjutnya kita akan mengisi kotak Chi-square test. dengan cara pindahkan warna honda scoopy (warna) yang ada pada kotak sebelah kiri ke dalam kotak sebelah kanan (Test Variable List) seperti pada gambar 6. Selanjutnya klik OKAnalisis
6. Selanjutnya klik OKAnalisis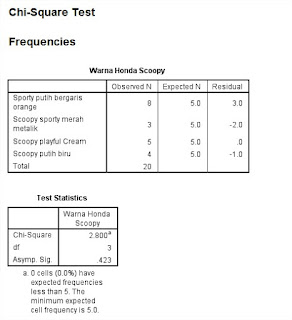 Dari hasil output dapat kita ketahui bahwa pada bagian Warna Honda Scoopy kolom Observed N masing-masing warna pilihannya berbeda, artinya warna Sporty putih bergaris orange 8 orang, warna Scoopy sporty merah metalik 3 orang, warna Scoopy playful Cream 5 orang, warna Scoopy putih biru 4 orang. jadi jumlah keseluruhan pemilih ada 20 orang. Pada kolom Expected N dapat dijelaskan karena pilihan responden tidak semua warna sama, maka masing-masing warna yang dipilih berbeda, jadi anggapan manajer dalam hal ini sudah mendekati kebenarannya (nilai 5 diperoleh dari 20 responden dibagi 4 warna). sedangkan Residual tersebut artinya sisanya dari masing-masing warna (nilai residual+expected atau nilai ecpected-residual maka akan menghasilkan nilai observed N setiap warna).Selanjutnya kita akan menganalisis bagian hasil Test Statistics, dari hasil tersebut diperoleh nilai Chi-square hitung 2.800. nilai tersebut kita bandingkan dengan nilai chi-square tabel, nilai schi-square tabel di dapat 7.81. dan nilai Asymp. sig (probabilitas) diperoleh 0.423.Tinjau pengujian statistik:Karena chi-square hitung < chi-square tabel yaitu: 2.800 < 7.815 dan nilai sig >0.05 yaitu 0.423. maka dalam hal ini H0 diterima.Kesimpulan:Berdasarkan pengujian statistik diatas maka dapat di ambil kesimpulan bahwa tidak semua konsumen menyukai sama-sama ke empat warna honda Scoopy yang ada, maka dalam hal ini pihak manajer pemasaran sudah benar anggapannnya.
Dari hasil output dapat kita ketahui bahwa pada bagian Warna Honda Scoopy kolom Observed N masing-masing warna pilihannya berbeda, artinya warna Sporty putih bergaris orange 8 orang, warna Scoopy sporty merah metalik 3 orang, warna Scoopy playful Cream 5 orang, warna Scoopy putih biru 4 orang. jadi jumlah keseluruhan pemilih ada 20 orang. Pada kolom Expected N dapat dijelaskan karena pilihan responden tidak semua warna sama, maka masing-masing warna yang dipilih berbeda, jadi anggapan manajer dalam hal ini sudah mendekati kebenarannya (nilai 5 diperoleh dari 20 responden dibagi 4 warna). sedangkan Residual tersebut artinya sisanya dari masing-masing warna (nilai residual+expected atau nilai ecpected-residual maka akan menghasilkan nilai observed N setiap warna).Selanjutnya kita akan menganalisis bagian hasil Test Statistics, dari hasil tersebut diperoleh nilai Chi-square hitung 2.800. nilai tersebut kita bandingkan dengan nilai chi-square tabel, nilai schi-square tabel di dapat 7.81. dan nilai Asymp. sig (probabilitas) diperoleh 0.423.Tinjau pengujian statistik:Karena chi-square hitung < chi-square tabel yaitu: 2.800 < 7.815 dan nilai sig >0.05 yaitu 0.423. maka dalam hal ini H0 diterima.Kesimpulan:Berdasarkan pengujian statistik diatas maka dapat di ambil kesimpulan bahwa tidak semua konsumen menyukai sama-sama ke empat warna honda Scoopy yang ada, maka dalam hal ini pihak manajer pemasaran sudah benar anggapannnya.